The Future of Data Engineering is No-Code
- John Morrell
- May 6, 2022

Talent shortages, a disintegrated modern data stack, and a continued programmatic approach to data engineering processes continue to hinder data engineering processes and drive up costs.
Multiple software development and engineering processes have been streamlined and become more agile over the past few years. A major contributor to this trend has been no-code tools. No-code not only enables agility but also allows team members in the business to participate more actively in development processes.
No-code tools hold the key to breaking the data engineering logjam and creating efficient and agile data engineering processes. Let’s explore what challenges organizations face for data engineering and how no-code tools can break them out.
Rising Data Engineering Costs
Perhaps the biggest reason for rising data engineering costs is the shortage of skilled data engineers. As we explored in this earlier blog, The Impact of the Data Engineering Talent Shortage, demand for data engineers is so high, and there are simply not enough skilled data engineers to fulfill this demand. This impacts data engineering in two ways:
- Data engineering costs rise as these skilled workers can demand higher salaries, and
- Without enough data engineers, project backlogs grow, and analytics projects become long and complex.
Two other factors contribute to the rising data engineering costs: the complexity of modern data stacks and that data engineering processes remain highly programmatic.
The Challenges of Modern Data Stacks
As many organizations have moved to cloud data warehouses and lakehouses, they have also rebuilt their data stacks. Gone are old-world, monolithic ETL tools that were the domain of specialized ETL developers. Those have been replaced by specialized tools – EL tools, data transformation tools, data catalogs, data observability tools – each designed for a purpose that organizations piece together.
Even though each specialized tool may be better than its old-world predecessor, this disintegrated approach to a modern data stack also creates complexity. Data engineers are forced to use multiple tools to get their jobs done. And the core aspect of what data engineers do – data modeling and transformation – remains a highly programmatic process.
Data Engineering is Still Highly Programmatic
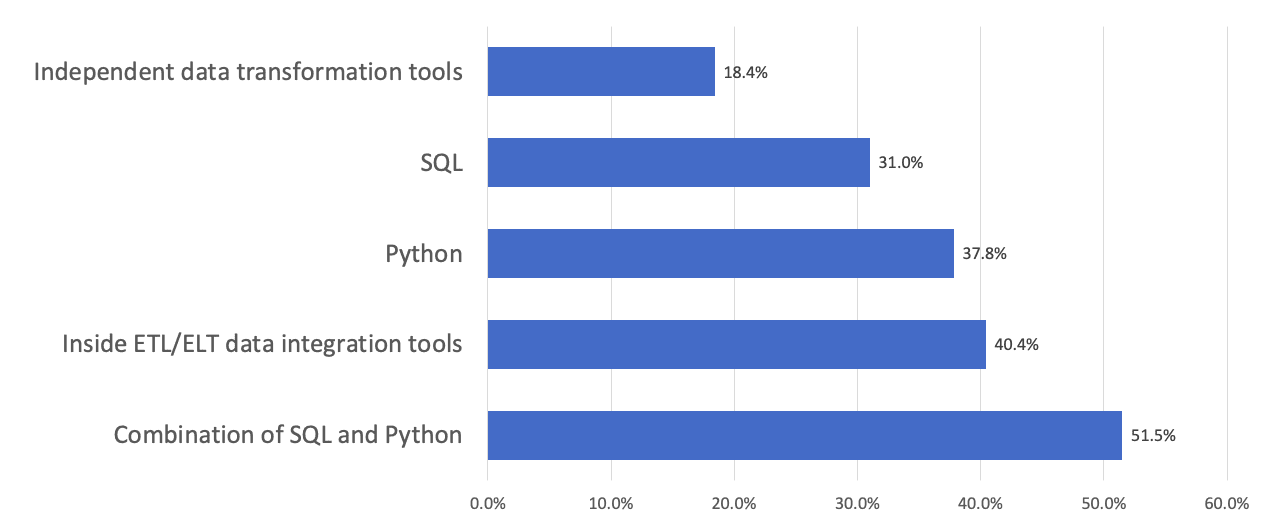
Datameer recently surveyed over 870 data and analytics professionals to get their thoughts on various trends and practices within their organizations. The survey revealed that most data engineering today is done via Python, SQL, a combination of Python and SQL, or in data integration tools, as indicated by our survey respondents (see chart below).
The No-Code Trend
The no-code tools trend is taking many different software markets by storm. Whether in mobile development, application development, digital transformation, process re-engineering, or other areas, no-code is gathering momentum in many different markets .
There are two main advantages to no-code tools. The first is getting more people to contribute to the process, share the workload, and create greater ability. The second is to facilitate greater collaboration around processes. With no-code tools, the old-world process focused on initial requirements gathering can be replaced by highly interactive and collaborative ones where more team members out in the business can contribute, ensuring the project’s successful delivery the first time.
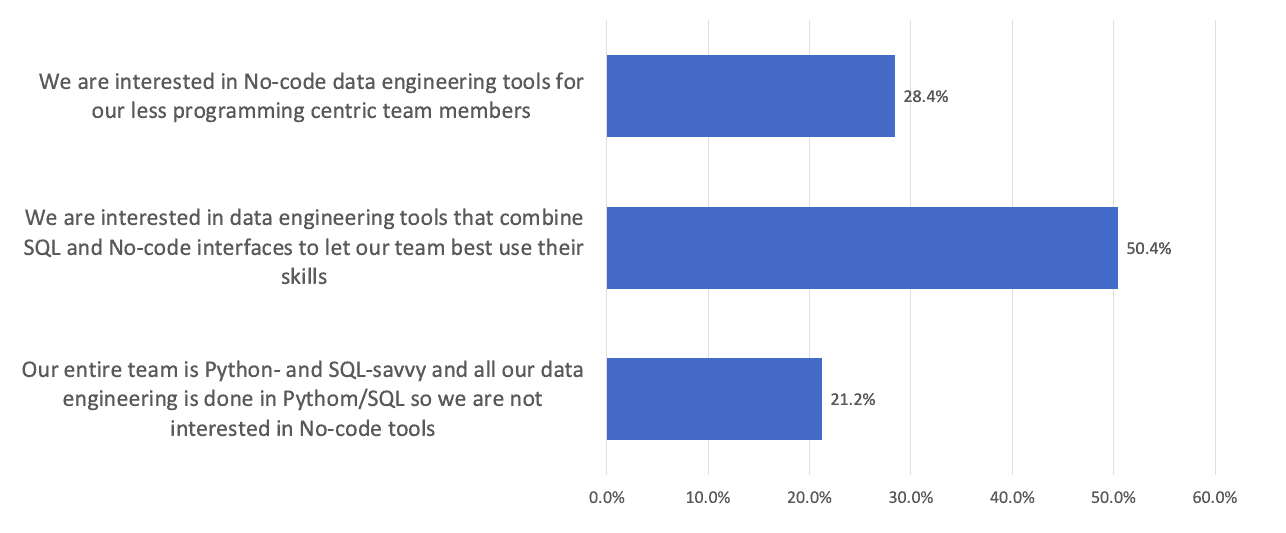
In the same Datameer survey, users were asked about their desire for no-code tools for data engineering and showed strong interest. Nearly 79% of respondents showed interest in no-code tools, with over 50% desiring a tool that combined SQL and no-code, which would allow teams to better share the workload and collaborate.
What is No-code for Data Engineering
Regardless of how your data engineering processes are performed, SQL coding is almost always involved, typically in a Python or Spark/Scala wrapper. Even if transformations are done within an ETL or ELT data integration tool, users typically must write SQL within the tool.
The ideal no-code toolset for data engineering does not ignore SQL; in fact, it embraces it. It would also embrace that other personas who prefer a no-code approach can get involved. Hence it might contain both:
- A SQL notebook-style interface where users can interactively write SQL, see results and then save the model/transformations in the cloud data warehouse, and
- A no-code interface where users can easily perform drag and drop operations on datasets as well as use wizard-driven formula builders to transform and enrich data
It is important that as users apply each step in their data engineering process, they get a rich profile of the data and can see the impact of each new operation they apply. This also makes the process agile and helps eliminate errors.
By combining both interfaces into one tool, users can best use their skills to transform their data, and non-programming citizen data team members can get in the act.
Collaboration is Required
The second way data engineering processes become more agile is through collaboration. Past processes where data engineers gather requirements then go do their work are replaced by an interactive process where a virtual team is constantly involved.
A no-code data engineering tool can facilitate shared workspaces where the virtual team works together. Team members can contribute, see models as they are being formed, comment or offer suggestions, and help in testing. In fact, who else to better test a data model than the analytics team member in the business who needs it for their insights.
Collaboration simplifies and speeds data engineering processes by:
- Getting more contributors involved in the process,
- Sharing the workload across model design and testing,
- Ensuring requirements are properly met the first time and allowing for fast requirements changes,
- Reusing or adjusting existing models to meet new analytics project requirements.
- Sharing knowledge about the data and how it is used to help other analytics team members and data engineers
Datameer
Datameer’s SaaS data transformation platform focuses on the T – transformation – in your ELT or ETLT stack. Datameer is the industry’s first collaborative, multi-persona data transformation platform integrated into Snowflake. The multi-persona UI, with no-code and SQL code tools, brings together your entire team – data engineers, analytics engineers, analysts, and data scientists – on a single platform to collaboratively transform and model data. Catalog-like data documentation and knowledge sharing facilitate trust in the data and crowd-sourced data governance. Direct integration into Snowflake keeps data secure and lowers costs by leveraging Snowflake’s scalable compute and storage.
Are you interested in learning more about Datameer and how it can deliver agility and collaboration for the “T” in your modern ELT data stack? Please visit our website or Sign up for your free trial today!


