Snowflake Data Science – A Blissful Guide for Data Scientists
- Jeffrey Agadumo
- November 15, 2022
Techpoint asserts that a massive 85% of big data/data science projects fail.
As a data scientist, this is undoubtedly one of the worst scenarios you can experience – spending time to build and deploy models only to observe wrong predictions that add no direct value to the business.
Sounds relatable?
We understand the pain data scientists go through in their work, and that’s why we came up with this Snowflake data science guide as a breath of fresh air for all you terrific data scientists out there.
This article will introduce Snowflake , its interrelation with data science, and the top 10 snowflake attributes for data science workloads.
Let’s Get Familiar With the “What is Snowflake?” Question
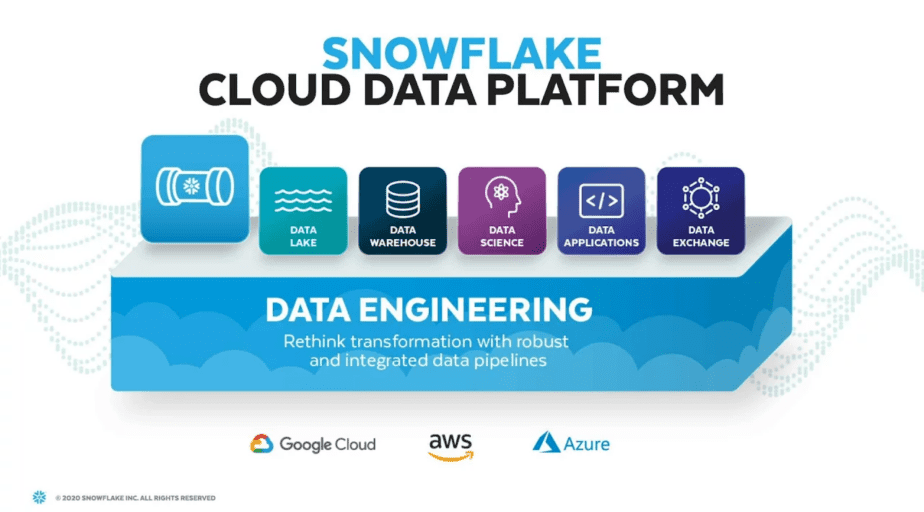
Snowflake is a unique platform that was built for the cloud. It is a massive parallel processing system designed to work in all three public clouds , natively and as a service.
It offers a variety of capabilities without compromising simplicity; scales up or down to deliver the most excellent Performance-to-Cost ratio.
Snowflake as a service does not require any installation, configuration, or management of hardware or extra software, making it perfect for enterprises that do not want to spend resources on the setup, maintenance, and support of in-house servers.
It allows you to consolidate your data and scale your compute separately.
The rising dependence on machine learning has created a demand for data science platforms that can help with ML models’ development, training, scaling, and deployment.
Snowflake tackles these use cases implemented globally, such as data engineering, data lake, data warehouse, data sharing, data application, and data science .
Let’s define data science.
What is Data Science and Its Importance?
Data science enables businesses to comprehend enormous amounts of data from several sources effectively and to gain insightful information for more informed decisions. Virtually all business sectors employ data science in business processes, such as marketing, healthcare, banking, finance, and other areas.
Common Problems With Traditional Data Science Processes
A survey put out by snowflake shows that most data engineers and scientists spend over 66 percent of their time carrying out data preparation activities as opposed to actual model building and hypothesis testing, i.e., the actual data science activities.
With the rapid explosion of data sources, it has become increasingly challenging to get the data from source to data scientists at the right time and in the proper format.
Some of the challenges that traditional data engineering/science teams face are:
- Difficulty in governing and securing Siloed data :
Finding and gaining access to accurate data tends to be time-intensive.
- Difficulty in putting models in production:
Some common causes are slow ETL/ELT due to resource contention or the cycle of data preparation and feature engineering taking days or even weeks.
- Lack of collaboration :
Isolated teams fail to generate value as there is no central space for collaboration between business users, data analysts, and data scientists.
Snowflake For Data Science – Top 10 Snowflake DS Attributes
With MPP and multi-architecture features, it’s safe to say that snowflake was built with data science workloads in mind.
This section will explore 10 snowflake data cloud attributes that support data science and ML activities.

An illustration of a typical data science workflow
- One place to access all your relevant data: Apart from the benefit of its ability to support structured and semi-structured data, batch and continuous processes. Snowflake lets customers quickly access and incorporate all relevant data to get the most predictive power out of your models.
- Improved pipeline performance & reliability: Instant scalability, no resource contention. Snowflake offers automated and scalable pipelines to accelerate data prep and feature engineering – at any scale. Reduce pipeline complexity and extensible data pipelines. It also allows an agnostic approach by enabling data teams to use their preferred language, e.g., SQL, Java, Scala, and Python.
- Streamlined architecture to unify teams around governed data: Snowflake allows customers to incorporate their native tools to build secure and actionable data science workflows. Connect Your ML tool of choice to snowflake data, run scalable and secure model inference, and share model insights with the team. Write model results in snowflake for business users and analysts to easily consume and act on ML-driven insights.
- Access industry data sets to enrich analytics capabilities through the snowflake marketplace.
- Fast processing engine with no operational overhead with snowflake’s multi-cluster architecture.
- Prepare data with your language of choice: Support for ANSI SQL and Java/Scala & python with Snowpark.
- Handle any amount of data or users: Multicluster compute architecture with auto-scaling requires zero manual operations.
- Profile and understand your data with speed: With its new UI, snow sight, snowflake offers a way to perform ad-hoc profiling and analyze your data on the fly.
- Adaptable to most machine learning practices: including Multi-modal, notebook-based, and automation-focused methodologies.
- Data governance: With role-based access and row-level security, snowflake assists in asserting governance on your data.
Running ML Workloads Using Snowflake
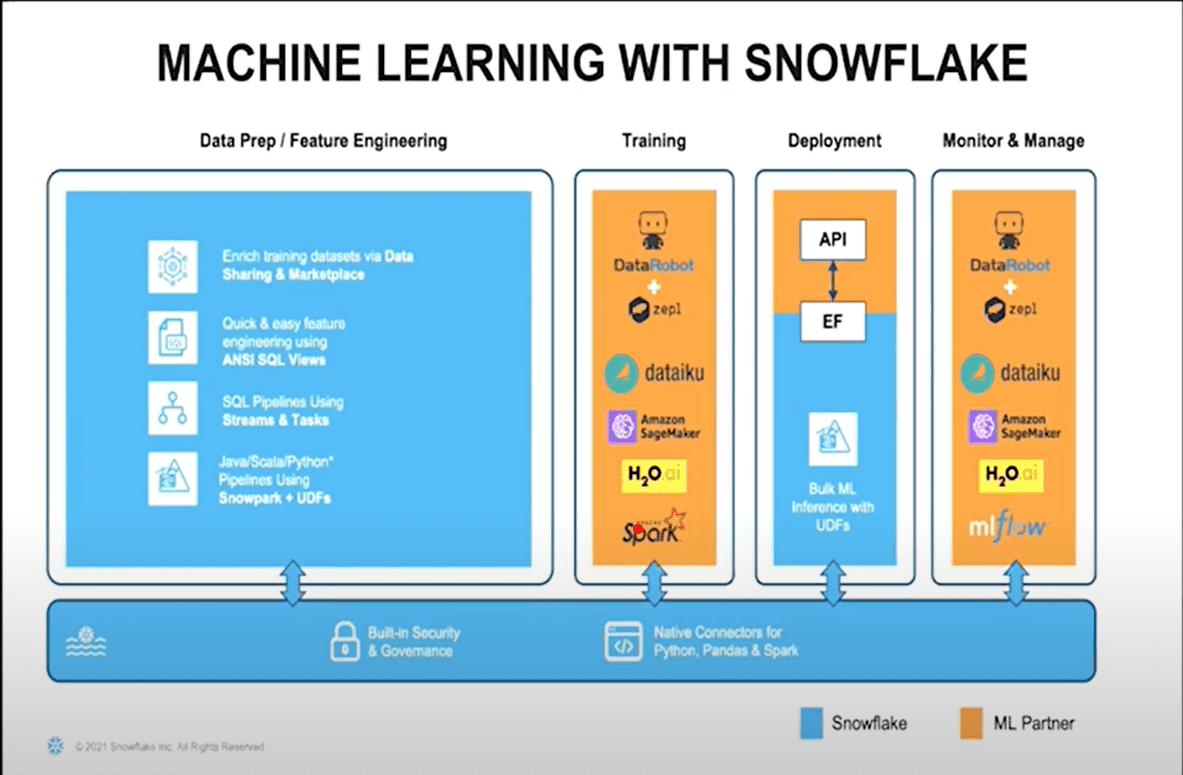
Previously, we discussed snowflake and its features for modern data science workloads, from collecting data to data preparation, training, deployment, etc.
In this section, however, we will map those snowflake features and tie them to a typical machine learning/DS workflow to better understand how snowflake supports our processes.
1. Data Prep/Feature Engineering:
With snowflake, we can enable massive feature engineering and data preparation capabilities using critical capabilities of Snowflake. Some of these include:
- Quick and easy feature engineering using ANSI SQL views
- Data enrichment and pipeline orchestration via external functions
- Transformation using stream and tasks
- Non-duplicate private boxes: You can create a full copy of data in production in seconds at no cost using snowflake’s Zero-copy cloning features.
- Transformation and CDC using streams and tasks
2. Training:
Strong partnerships with key data science software industry players, such as DataRobot, Dataiku, Amazon Sagemaker, spark, H2oai, etc.
With these tools, you can train your data while maximizing the snowflake engines as your base.
Additionally, Snowflake offers native connectors allowing customers to bring in native tools of their choice.
3. Deployment:
To ensure all the training on the datasets you have done is okay, snowflake enables you to deploy these models as an API endpoint and consume via external functions in snowflake. You can also make an in-place inference by deploying them as JARs.
4. Monitor and Manage:
Snowflake partners with data science software at an executive and product level to enable you to monitor, manage and iterate through the process, making sure that any model which becomes stale, for example, is automatically brought into purview and kept up to date.
By now, I hope you’re convinced that if you’re not already using the Snowflake platform, you are most likely missing out on the optimization capabilities a modern data platform can offer to your traditional DS workflows.
Additional Resources & Best Practices on Data Engineering With Snowflake:
As this is a guide, it will only be proper to end with helpful resources on data engineering and data science with snowflake.
A few best practices to implement while leveraging snowflake for data science are:
✓ Enabling your pipeline to handle concurrent workloads.
✓ Using data streaming instead of batch ingestion
✓ Invest in tools with built-in connectivity like Datameer
✓ Build a data catalog into your engineering strategy.
✓ Rely on data owners to set security policy.
Additional resources you might be interested in:
Use cases
https://www.snowflake.com/en/data-cloud/workloads/data-science-ml/
Learnings
https://www.snowflake.com/data-cloud-academy-data-scientists/
Wrap-Up
As a data scientist, your primary concern is not just to deliver results but to answer the most crucial questions related to data in your organization.
Cleaned, arranged, and processed data is the foundation for practical data science.
Regarding both method and process, how you model and perform your data preparation is key to upstream data science activities.
Why do all of these things in Python code?
Datameer SaaS Data Transformation is the industry’s first collaborative, multi-persona data transformation platform integrated into Snowflake.
With tools like Datameer, your DS team can go from raw data to prepped datasets in minutes.
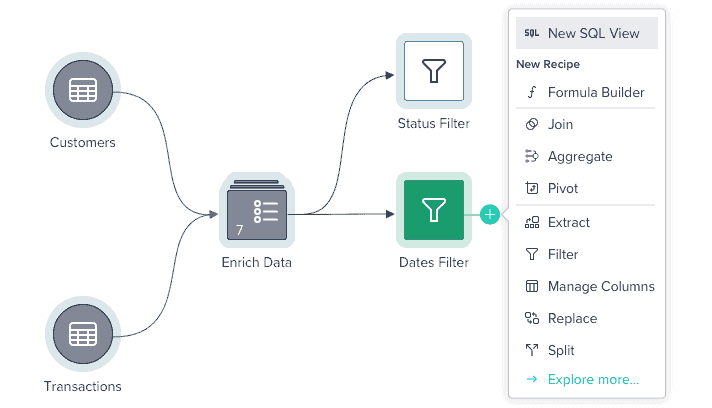
With Datameer’s SQL visualization and collaborative modeling features, you can bring data science into the mainstream of your analytic processes and drive a higher ROI.
Curious ?
Check out our demos here, or get started with your free trial .


