Regulatory Compliance as a Strategic Weapon – conclusion
- John Morrell
- June 13, 2018

Regulatory Compliance as a Strategic Weapon
Part 4: Meeting Critical Requirements
One common topic in regulatory data compliance is the notion of a “single version of the truth” (or SVOT). When addressing regulatory compliance questions, banks and other large institutions want to rely on a single set of data to prove compliance, rather than having to stitch multiple data sets together. This idea developed out of the chaotic V1 architecture era and is meant to reduce the risk for error and delays.
However, a recent article by Thomas Davenport in the Harvard Business Review has somewhat debunked the idea of an SVOT. Instead, Davenport suggests having two different data strategies: a defensive data strategy and an offensive strategy.
Offensive vs. Defensive Data Strategies
Offensive and defensive data strategies have different objectives. The objective of a defensive data strategy is to keep data secure and private, while also maintaining proper governance and regulatory compliance. This requires understanding all requirements and effectively implementing the right processes to meet them. In the end, you create an SVOT data set to share with regulators.
With an offensive data strategy, the goal is to improve the firm’s competitive position, enter new markets, or grow the business. In these cases, you may want to manipulate data in a different way, or at least look at it through a different lens. An institution doesn’t necessarily have to comply with a “single version of the truth” when taking on these initiatives. Therefore, a firm could end up with multiple versions of truth.
The defensive data strategy is usually the responsibility of the data engineers and Chief Data Officer. The offensive strategy, however, is best in the hands business analysts. Analysts need the freedom to create new “versions of a truth” that help them develop new business initiatives.
The offensive and defensive data strategies are not completely separate. Ideally, the offensive version of the truth is derived directly from the defensive version. In other words, the defensive version is the “common shared model” of the data, which analysts then copy and manipulate to fit their business needs.
Benefits of Offensive and Defensive Data Strategies
There are a few key benefits to having multiple versions of truth for your data. First is the balance of control and flexibility for offensive data initiatives. Controls over the offensive data are not too strict, but because the derived from the SVOT, it is not too flexible, either.
The second benefit is the balance of trust and uniqueness in the data. You know the data has been confirmed and verified, but it can also be transformed into something unique for business initiatives.
Having an offensive and defensive data strategy is the kernel of the strategic advantage that can be derived from regulatory compliance. However, institutions need the right tools to make this idea a reality. That is where analytic data management comes in.
Analytic Data Management for Compliance Architecture
Business today need to think beyond regulations and focus on analytic data management.
Analytic data management for compliance architecture gives institutions the ability to take and use all available data for strategic business uses. There are several key features of analytic data management architecture:
- Multiple Pipelines. Institutions need the ability to create pipelines from all available sources of data. This means incorporating the SVOT data set with all other managed data so it can be used by data scientists and business analysts.
- Data Lake. These data pipelines should be run and managed directly inside your data lake. Moving volumes of data this size costs considerable money and time. You need to the ability to keep and effectively manage all data in one place.
- Ad-Hoc Exploration. Compliance architecture should support ad-hoc exploration of the data. Data scientists and business analysts need the ability to explore, understand, and do “forensics” on the data at will.
- Recording Metadata. Any information about data usage must be recorded into enterprise governance catalogs. Often, these catalogs are needed for compliance reporting processes.
- Integration and Movement. Institutions need the ability push data into other tools or to other locations in the organization.
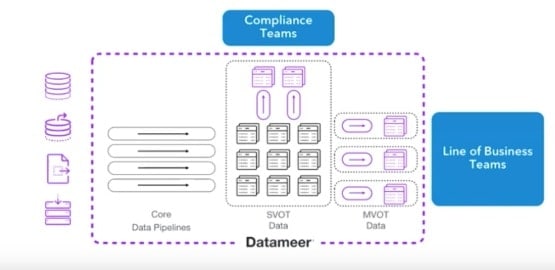
Core Data Pipelines
The primary pieces of infrastructure in the analytic data management architecture are the core data pipelines. Core data pipelines feed all data to the SVOT data set and fuels the compliance process.
But once the data in one place, line of business teams can use it to drive new initiatives. These teams can create new pipelines– derived from the SVOT data– that are specialized to their own needs.
This is how defensive and offensive data strategies work together. Businesses start with a defensive strategy– gathering all data in one place for compliance– and evolve to a defensive/offensive strategy where they can use that same data to drive new initiatives within the business.
Full Data Lifecycle Platform
To meet the needs for regulatory compliance as well as proactive analytic data management, institutions need a platform that covers the entire lifecycle of their data.
This platform must have a number of critical capabilities. It has to enable automation, security, and governance while also managing enormous amounts of data. It has to allow data engineers and business analysts to create their own data pipelines, ranging from simple integration and blending; to data preparation; to advanced analytic enrichment. Your team needs the ad hoc exploration capabilities to dig in and understand what the data is saying, and then the ability to let any downstream tool consume the end data they’ve developed.
Let’s look most closely at the capabilities needed in a full data lifecycle platform. These capabilities are best broken up into two broad categories: Functional and Control.
Functional Capabilities
Multi-source, large-scale aggregation
Institutions need to aggregate large volumes of data that come from multiple sources in multiple formats. The other challenge here is automating the aggregation of this data.
Agile Data Modeling
The platform should have an agile modeling environment that allows a firm to create pipelines that are both flexible and powerful. It has an interactive interface that allows them add functions and change the data model, then immediately see the results. If the results aren’t what they’re looking for, they can instantly revert back to a previous version and try again.
Continuous Visual Feedback and Advanced Curation
Teams need continuous visual feedback as well. They need to not only see the changes in data when new functions are applied, but also create charts that visualize the shape of that data change. They also need the ability to do more advanced curation, like time series or windowing analysis. These types of analyses can have a major impact on the data set.
Smart Enrichment
Smart enrichment, which involves running algorithms across data sets, can be even more effective at finding relationships within the data. Ad hoc exploration is critical here. Your team doesn’t just need to aggregate data and generate reports, but dive in to explore anomalous trends and understand why they are happening.
Ad-Hoc Data Exploration
Ad-hoc data exploration gives scientists a chance to view data across any possible dimension, value, subset, or attribute. To achieve this, a platform needs an interactive, dynamic, indexing-style system gives you the ability to explore billions of records while also keeping response times down to mere seconds.
Once a data scientist finds exactly what they are looking for, they can simply press a button and produce a new data set along those precise metrics.
Collaboration and Reuse
Finally, a platform must enable collaboration and reuse. Once a data engineer creates the SVOT– a common shared model– individual analysts need the ability to produce derivatives of their own that link back to that model. Then the analyst can add their own levels of enhancement and enrichment around the model to produce a final data set that is specific for their particular function and their specific initiative.
The purpose of these functional capabilities is to liberate your business analysts, giving them the data they need to freely do their jobs. This requires cooperation between the data engineer and the business analyst. The data engineer creates the data sets that the business analyst then consumes, explores, refines, and eventually uses for their very specific needs.
Critical Control Capabilities
The other set of key capabilities are best described as “Control” capabilities. Control capabilities include automated operations, highly scalable execution, and most importantly, security and governance.
Strong security ensures your data is encrypted, physically in the right place, and used in the proper methods. You need a regulation compliance platform that has:
- Role-based security
- Enterprise security integration
- Encryption and obfuscation
- Secure impersonation
You also need data governance capabilities to make sure you understand where and how the data is used. Critical governance features include:
- Usage and behavior auditing
- Data retention policies
- Full Lineage
- Enterprise governance integration
These capabilities ultimately help you answer the questions, “Where did this data come from?”; “How is it manipulated along the way?”; “How were the end results produced?”; and finally, “Where did those end results go?”
Both functional and control capabilities are necessary to unlock the strategic advantage of regulatory compliance. The calling card of V3 architecture will be the combination of all the capabilities in the core business.
Customer Case Study
Challenge
In 2016, a leading Canadian bank faced a set of very interesting business challenges. First, there were staring down regulatory compliance deadlines for BCBS 239.
Second, their market was getting incredibly competitive. At the same time, the bank wanted grow internationally and reach new markets across the Americas, Europe, and Asia.
Finally, they faced major demographic changes. There was a new generation of customers– millennials– who were coming of age and wanted to bank in a different way. They didn’t want to go to a branch; millennials wanted to bank online and from their smartphones. The bank had to wrap their arms around the challenge of serving this new breed of customer.
Business Challenges
- Meet regulatory compliance deadlines
- Increasingly competitive market
- International expansion
- New generation of customers
Along with these business challenges, the bank also faced extreme technical challenges. They had to manage tremendous volumes of data, both for their regulatory compliance and to drive new initiatives within the bank. This data came from a number of different sources and in a number of different forms; they needed to rationalize and normalize all of this data together.
The questions the bank wanted to ask were extremely complex and nuanced. The bank went from tracking 50 attributes to over 500 attributes for specific data sets. At this point the question became, “Which of these attributes– and ranges of attributes– are the most important to us?” The bank needed to dig deeper into their data to get the answers they wanted.
Technical Challenges
- Huge volumes of data
- Multi-source and -variate
- Complex questions
- Need to dig deeper
Solution
The bank first focused on regulatory compliance for BCBS 239. The first step was to create a risk data lake. The bank built out an RDARR platform on top of their data lake using Datameer. They aggregated all of their data in one place so they could facilitate and operationalize their BCBS 239 reporting.
The bank also gave their analysts access to the data lake for ad-hoc exploration. When analysts identified a problem to solve, they could dig into the data and explore it in different ways and from various angles. So while the data lake enabled regulatory compliance, it also enabled a wider variety of uses across the bank.
They quickly grew the data lake to support a variety of different use cases. By focusing on one specific initiative at a time, the bank expanded their data analytics program in a responsible way. They gave self-service access to business analysts, but did so in a way where the data was secure, governed, and monitored.
The data itself was trustworthy because the data platform automatically recorded metadata. This told other users who else used the data, why it was published, and how it should be used. Other users could confidently reuse the data again if they had the privileges to do so.
Results
The bank implemented their BCBS 239 compliance process in a matter of months. Then they were able to spread into seven different lines of business over the following month. Their data lake is now a source of excellence for the company. Over 700 analysts use the data lake to create new data sets and solve problems interactively.
The bank has over 1,000 published data sets that are reused across the business, which has created faster analytic cycles. They’ve reduced the risk reporting times for BCBS 239 and other compliance regulations. They also reduced the overall cost of reporting by removing manual aspects of the process, thus removing the “risk” from their risk reporting.
Conclusion
The transformation from V1 to V3 regulatory compliance architecture is filled with confusion, obstacles, and complex technical challenges. The key to overcoming these hurdles is the strong internal mobilization and alignment of your teams. Every stakeholder– from leadership to front line employees– needs a clear vision of the “future state” of your compliance architecture.
Part of that vision is understanding how regulatory architecture can become a strategic advantage. By first developing a single source of truth, business analysts can then create new models to serve their specific initiatives without sacrificing strong security or governance. This type of freedom and power requires a certain set of capabilities around both functional and operational activities.
As we saw in our case study, the right tools can enable a company to move quickly from regulatory compliance success to strategic data excellence in a matter of months.


