Four Ways to Overcome Data and Analytic Challenges in the Insurance Industry
- John Morrell
- April 6, 2018

I chaired a panel last week at the Corinium Chief Data and Analytics Officer, Insurance event this week in Chicago. The entire event was very revealing into the data and analytics issues of the insurance industry.
One key takeaway was that while the insurance industry does not produce physical assets, insurance carriers should be in the business of producing one key asset: Data. Insurers have tremendous volumes of data about customers, risk, losses, policies, claims, and more that can be transformed into real business value.
Like manufacturers who optimize their business around the production of their physical assets, the key to optimizing an insurer’s business is to streamline the production and use of data. Similar to how high-performing organizations embrace digital transformation and use data assets to execute more effectively in the market, insurers that effectively produce and utilize data assets will be the higher performers in their sector.
The insurance industry faces many unique challenges due to regulation, individually operating lines of business, varying depths of data sources, and more. Modern digital age competitors are challenging incumbents’ business models, making them embrace digital transformation or become extinct.
One of those major challenges is putting a broader data strategy into place to make more business-ready information available to analysts and business teams. A 2016 study by Willis Tower Watson surveyed insurance industry executives about their use of big data. One question asked probed into the challenges and barriers the executives see. Second, behind people skills is data availability (see figure 1).
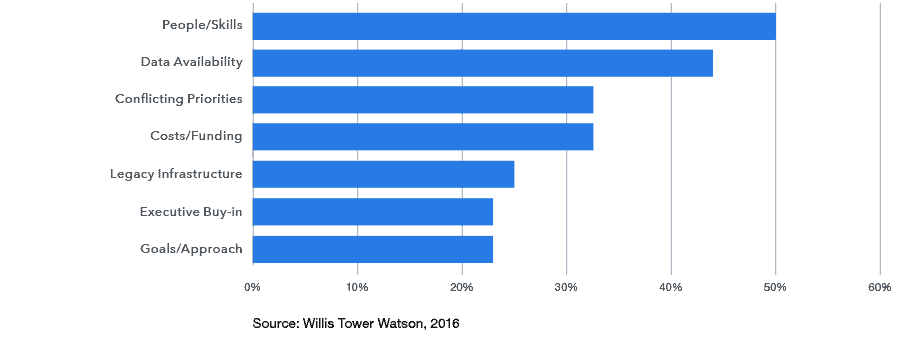
Figure 1. Barriers and Challenges to Big Data Analytics
Let’s explore four ways insurance companies can expand their data strategies to drive forward-thinking and unique analytics to propel them to become high-performing organizations and leaders in their markets.
1. Break Down Those Silos
Many insurance carriers, like other industries, have multiple data silos dispersed across their organization. In the insurance world, this happens due to independently operating product teams or business lines, which focus on their own data needs and performance. In some cases, these lines of business came via acquisition.
Data owners, typically the business line, place barriers to sharing data across the business through slow, cumbersome IT resource-heavy processes. Lack of resources and complex processes are to blame for carriers creating an effective enterprise-wide data strategy.
Carriers can create a modern data management architecture that can break down data silos and create an aggregated view of various business aspects. With the proper data pipeline platform:
- IT and data teams become enablers and leaders, facilitating the proper sharing and use of data
- Centralized or business-embedded analytic teams can create their own data pipelines, unique to their needs, to drive faster insights and explore new questions
To quote one of my panelists, “I don’t know what I don’t know.” And expanded access and use of data help explore the unknown.
2. Aggregate to Get 360 Degree Views
Data silos present a data architecture challenge, regardless of industry. In the insurance world, they prevent carriers from getting complete views on customers, risk, losses, product performance, and more.
A 2016 study by Willis Tower Watson surveyed insurance industry executives about their potential use of big data. In this study, executives revealed where they were using big data today – 2016 – and where they expected to use big data two years later – 2018 (see figure 2).
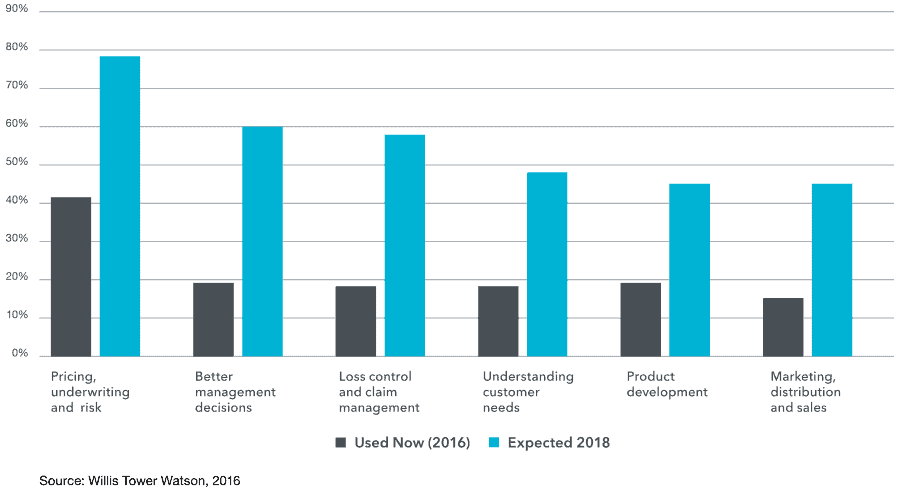
Figure 2: Use Cases for Big Data Now and Two Years Later
Not surprisingly, the top areas were getting better overall views of:
- Pricing, underwriting, and risk
- Potential losses and claims
- Understanding customers
Getting to the heart of these issues requires an agile enterprise data strategy and data pipeline platform that can aggregate the data from various silos and facilitate faster delivery of business-ready information to analytics teams. This allows business analysts to get 360-degree views of customers, loss potential, and more to drive the next best actions that increase overall customer lifetime value and make informed decisions to assess total risk exposure.
Banking firms have recognized the need to get broader perspectives on customers and risk, the former driven by competition and later driven by regulatory compliance. In the end, they turned to agile data pipeline platforms to facilitate faster aggregation and organization of data.
3. Don’t Strive for Perfection
In many ways, the final presentation at the CDAO Insurance event was the most revealing. One very interesting point by the speaker, Gene Boomer, Senior Enterprise Data Architect from Protective Insurance, was that insurers should not strive for perfection but rather achieve the “most.” This meant:
- Delivering data in the most timely manner
- Gather the most complete data
- Creating the most trust in the data
In this case of insurance carriers, and quite frankly any industry, more is always better. Creating the perfect data architecture and data delivery processes is, in practical terms, unachievable.
This means carriers should strive to enable broader data pipelines and more access to data, one step at a time. Start with high-value use cases, focusing on the data needed to deliver those. Expand from there to reach other areas of the business. Banks often started in risk or customer-facing processes, then drove adoption in additional lines of business.
The greater the adoption and use of data via these pipelines, the more trust will be built in the data that is being delivered. After all, trust is a function of how analytic peers view the usefulness of the data. Trust will be managed socially via self-built data pipelines that analysts can properly share.
4. Govern with an Even Hand, not a Stick
In a regulated industry such as insurance, governance will play a vital role in effective data architecture. Data privacy and governance issues often allow owners of data silos to put up barriers to data sharing.
Governance, however, needs to be managed with an even keel and with an eye towards driving broader use of data. I’ve encountered some organizations so fixated on data privacy and security that it paralyzes the use of data assets to drive business transformation and execution.
Yes, data security and privacy are important, but this can effectively be balanced with data sharing. A more appropriate and positive way to describe how you govern data is permissible to access. Provide access to those who can properly use the data in effective business situations and don’t take an attitude of blocking first.
As insurance carriers enter the early stages of a data strategy, it is important to facilitate use cases where deep governance is less of a requirement and will not be a barrier to adoption. Broader governance policies can be defined and implemented over time as greater data democratization is facilitated.
It is also important to recognize that governance is 50% process and 50% features in the data pipeline platform that enable proper governance. Governance processes are often unique to each business and organization and need to be tailored to those specific needs.
Your Data Transformation is Key
Effective insurance analytics starts and ends with clean, organized, and processed data. How you transform your data is critical to this, in terms of both process and how. Insurance analytics are assembled by analyzing complex and diverse datasets that need to be cleansed, blended, and shaped into final form. Often times this involves high degrees of collaboration between data engineering and analytics teams. It also requires rich data documentation to back up compliance processes.
Datameer is a powerful SaaS data transformation platform that runs in Snowflake – your modern, scalable cloud data warehouse – that combines to provide a highly scalable and flexible environment to transform your data into meaningful analytics. With Datameer, you can:
- Allow your non-technical analytics team members to work with your complex data without the need to write code using Datameer’s no-code and low-code data transformation interfaces,
- Collaborate amongst technical and non-technical team members to build data models and the data transformation flows to fulfill these models, each using their skills and knowledge
- Fully enrich analytics datasets to add even more flavor to your analysis using the diverse array of graphical formulas and functions,
- Generate rich documentation and add user-supplied attributes, comments, tags, and more to share searchable knowledge about your data across the entire analytics community,
- Use the catalog-like documentation features to crowd-source your data governance processes for greater data democratization and data literacy,
- Maintain full audit trails of how data is transformed and used by the community to further enable your governance and compliance processes,
- Deploy and execute data transformation models directly in Snowflake to gain the scalability your need over your large volumes of data while keeping compute and storage costs low.
Learn more about our innovative SaaS data transformation solution by scheduling a personalized demo today!


