Dealing with Variant Columns in Snowflake
- How-Tos FAQs
- September 22, 2022

There are many ways to store data in Snowflake, and one of the most flexible is to use variant columns. Variant columns can store any type of data, including arrays, objects, and even other variants, making them ideal for storing data that might be of any type or for storing data that might change types over time.
Variant columns are also great for storing data that doesn’t fit into a traditional database schema. For example, you might have data that includes both text and numbers or data that includes images and other binary data. By using variant columns, you can store this data in Snowflake without worrying about fitting it into a specific schema.
Variant columns are a bit of a pain in the neck when it comes to working with data in Snowflake. They can cause all sorts of issues, from data being truncated to simply being unable to query the data.
Of course, you could always just ignore the variant column altogether. But, if you’re dealing with a lot of data, that could cause some serious performance issues. So, it’s probably best to deal with the variant column somehow.
Dealing with Variant Columns in Datameer
Datameer is a powerful data analytics platform that makes it easy to work with variant data types. With Datameer, you can easily query, transform, and visualize your data, no matter what the data type is.
- One way is to use the COPY INTO command to load the data into a staging table. From there, you can use the ALTER TABLE command to change the column’s data type to VARIANT.
- Another way to deal with variant columns is to use the CREATE OR REPLACE VIEW command. This will allow you to query the data in the column, but you will not be able to modify the data itself.
See the snippet below:
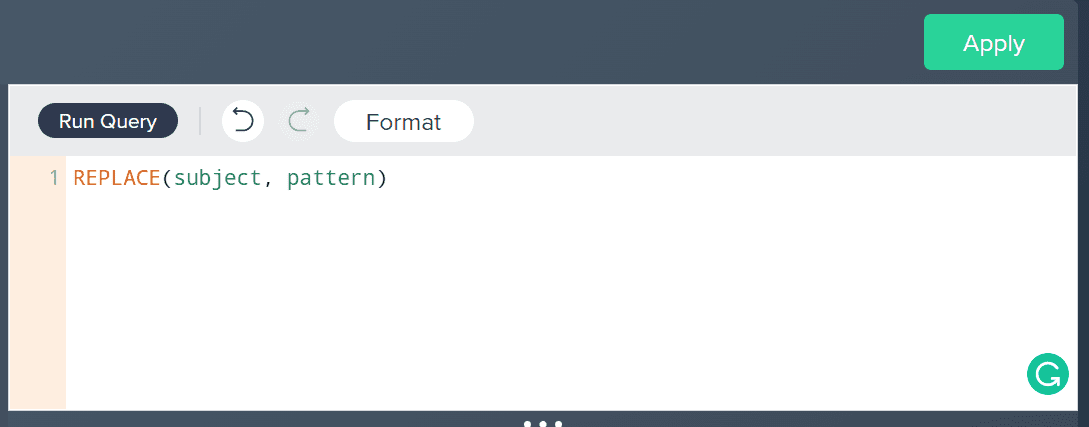
- You can also add dummy code to the column. This means creating a new column for each value in the original column. For example, a column might be called “Color” and have the values “Red”, “Green”, or “Blue” in different rows. So, for the “Color” column, you would have three new columns: “Color_Red”, “Color_Green”, and “Color_Blue”. Each row would then have a “1” in the column corresponding to the value in the original column, and zeros in the other two columns. Dummy coding can be a good option if you plan to use machine learning algorithms that can’t handle categorical variables (most can now, but some can’t). It can also be helpful if you want to see the individual effect of each value in the column.
- If the column is important to your analysis, but you would rather not dummy code it, you can use a technique called “One Hot Encoding”. It’s similar to dummy coding, but you create new rows instead of creating new columns for each value. So, if you had a “Color” column with three values, you would end up with three rows of data. One Hot Encoding can be a good option if you want to keep all the data.
- Use the Column Transformation feature to convert variant columns to the data type you need. This makes it easy to work with data in Snowflake, even when it includes variant columns.
See the snippet below:
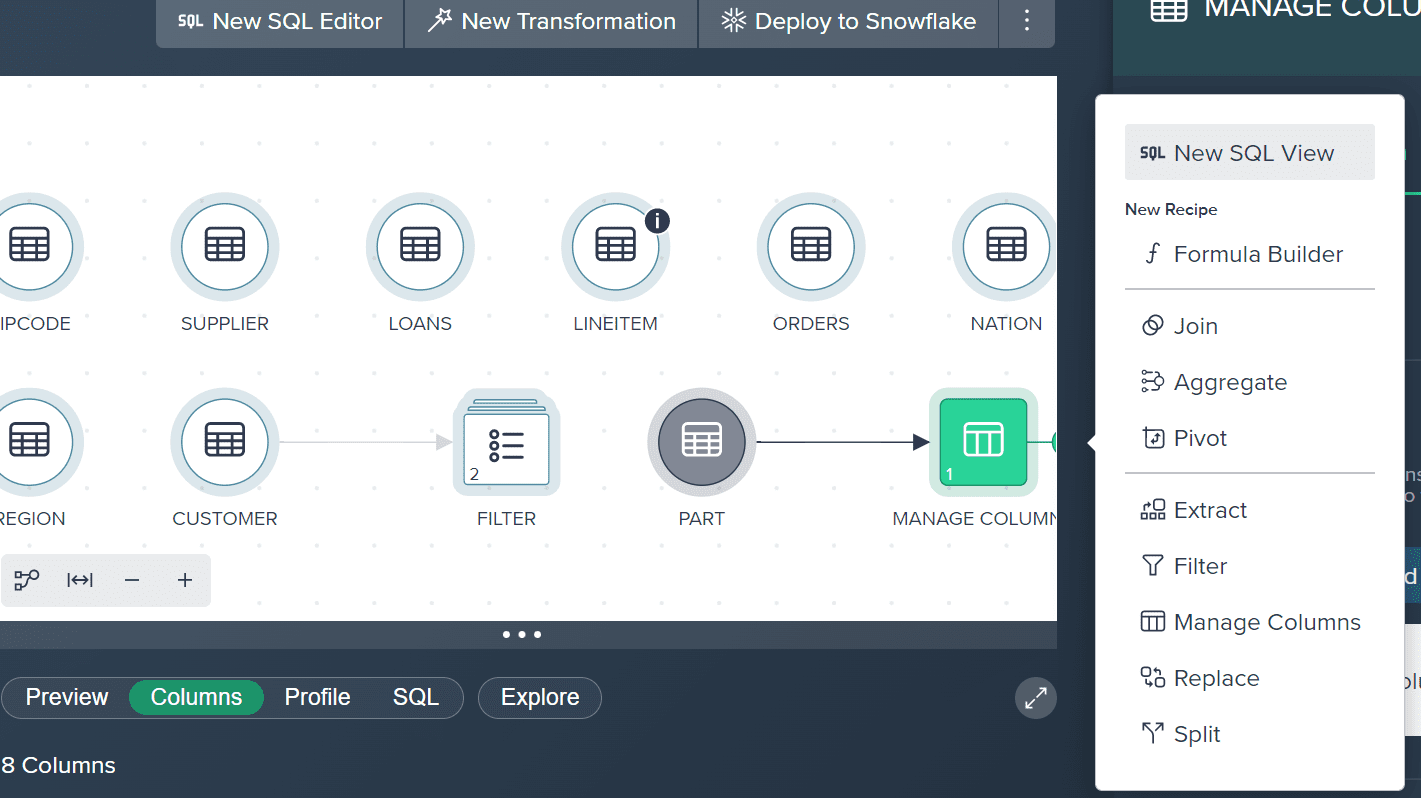
You can easily transform a variant column with Datameer.
Learn more by visiting Datameer website, or get started immediately with a free trial.


