dbt Snowflake: When dbt Isn’t The Best Tool for Your Analytics
- Jeffrey Agadumo
- December 28, 2022

This article explores the features of dbt in data transformation, the dbt-Snowflake integration, and when dbt might not be the best tool for the job.
If you’re a data practitioner looking for guidance on whether dbt is the right tool for the ‘T’ in your ETL pipeline , look no further! We will be providing insights that address this concern.
Why is dbt so Popular?
Firstly, dbt is a tool used to transform and ready your data for insightful analytics, regardless of the source or format of the data.
It is an open-source command line tool that enables data analysts and engineers to transform data in any data store. Dbt simplifies the analytics engineering workflow by building and implementing hassle-free complex data pipelines.
To answer the popularity question, dbt secured a funding of $222 million at Series D, currently has over 9,000 companies adopting the open source dbt Core, and 1,800 companies adopting the enterprise dbt Labs.
Dbt is fast becoming the industry standard for data transformation and ad hoc analyses. Here are some features that make it so popular:
1. SQL-Based Framework
The dbt framework is built primarily on SQL, and you can implement it with Jinja. With a few SQL queries, you can transform large data sets seamlessly across a wide range of use cases in the Modern Data Stack .
2. Version Control
Dbt uses Git version control system to enable data analysts to save and revert to code versions for models, hooks, and macros in a project.
It also keeps track of subsequent changes made to this code and can roll back (undo) a change that breaks functionality in the code.
3. Test Driven
Testing is an out-of-the-box feature in dbt. Once installed, you have access to ready-made tests like unique, not_null, and accepted_values, as well as other data and schema tests using the “test” command on the command line.
4. Modularity
With dbt, analysts can create models by writing SQL queries stored in files (modules).
Data models created can be reused on as many datasets as needed. It also allows you to set up templates (macros) using Jinja, which can be shared and reused across all your data teams’ operational workflow.
5. Ad hoc Analysis
Upon installation, there is an analyses folder in dbt for dbt analytics, which allows you to write SQL queries that may not fit into your models.
You can compile files containing such queries (using the ‘dbt compile’ command) to produce data sets for analysis purposes only, i.e. they cannot be deployed.
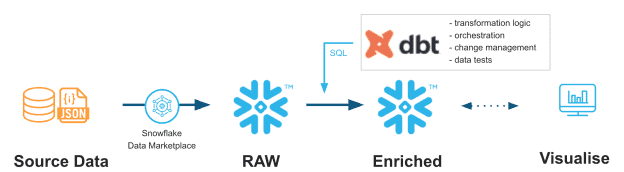
The Dbt-Snowflake Handshake
Dbt integrates with Snowflake , combining each other’s strengths to give a functional data transformation experience.
Below are the features that make the dbt-Snowflake integration seamless:
-
Multiple data teams, one universal language
Dbt works on Snowflake, which takes care of the entire data transformation process across multiple teams, and the only coding skill required is SQL.
-
Scalability made easier
When creating a dbt model in snowflake, analysts can define the Snowflake warehouse size that would be right for their model using snowflake_warehouse: x_small, giving them control over the run times and helping the company reduce costs.
-
Maintain multiple environments for data models
Analysts can create and maintain separate development and production environments for running dbt models by using targets to specify which environment to run the models.
Attestations from industry-leading directors on the power of dbt and Snowflake in action:
Ben Singleton, Director of Data Science & Analytics at JetBlue.
“The new workflow with dbt and Snowflake isn’t a small improvement. It’s a complete redesign of our entire approach to data that will establish a new strategic foundation for analysts at JetBlue to build on.”
Ryan Goltz, Principal Data Architect, Fortune 500 Oil & Gas Company .
“With Snowflake and dbt, the people who have the business problems now have the tools to go and solve their business problems.”
When is dbt Not the Right Tool for the Job?
While DBT is currently a market favorite, several catch-ups keep it from realizing its objective of enabling analysts to perform their transformations without the assistance of data engineering teams.
Chief among these are:
1. Steep Learning Curve
dbt uses SQL queries to build models and Jinja – a python engine – to create reusable templates. These coding languages require time and practice from data team members who don’t code.
In addition, users need knowledge of dbt commands to carry out operations such as running projects, compiling SQL files, and version control.
Although dbt cloud offers a graphical user interface for performing many command-line operations, data practitioners must be skilled at coding and the command-line syntax to fully utilize dbt features.
2. Technical User Experience
Dbt stated that a code-based UI is best for creating complex logic to analyze data.
When using dbt in an IDE on a large project with a complex scope, it becomes difficult to maintain the project and the environments in which it runs.
For instance, because the actual SQL code is abstracted by the macros, having multiple macros in your model can complicate your project and make your dbt models harder to understand for both technical and non-technical users.
3. Sharing Difficulty for Non-Technical Team Members
When working in a team, models must be easily accessible to all team members. Dbt uses Git for sharing models and macros in a repository.
However, all git operations are primarily performed on the command line. Hence, all team members must be technical enough to type out operation-specific commands to access and edit projects hosted on Git repositories.
4. Data Profiling
Data profiling is a principal part of data transformation, particularly as the volume and complexity of data sets increase. During transformation, data profiling helps team members understand datasets better and determine the next steps to take in the transformation process.
Dbt does not offer any features for data profiling but instead provides the user with a snapshot of the data from the project’s last instance. This proves challenging as users cannot quickly identify invalid or missing fields and values when writing SQL code.
Click here to learn more about missing features in dbt.
The Perfect T – Tool for Non-Technical Business Analysts
If dbt is the T in the ELT process, then Datameer is your T++.
In a modern data stack, team members who don’t have SQL knowledge need a data transformation tool that offers seamless integration with a cloud-based warehouse like Snowflake and a no-code interface that is easy to navigate for data analytics.
Datameer Cloud is that tool!
If the above were all Datameer had to offer, that would be a lot compared to dbt, but there’s more. Datameer provides several features that go beyond the components of DBT, such as:
-
Options for SQL code, low code, and no code
Datameer users do not need to be SQL experts. Datameer supports SQL as well as no-code data modeling. Whether you are a data analyst, a business operations expert, or an analytics engineer, Datameer has a UI for everyone.
-
UI that resembles a spreadsheet
Datameer has a spreadsheet-like UI with drag-and-drop functionality and “Smart Analytics” machine-learning capabilities to help you create powerful analytics engineering workflows.
-
Collaboration
Datameer strengthens more collaborative data transformation workflows because it supports hybrid (both SQL and no-code) teams. Users can collaborate on large and complex data models within the same workspace without using Git.
-
Data Cataloging
Datameer offers rich data cataloging with a robust API that allows you to access catalogs on different platforms.
Also, data generated on other platforms feedback into the data catalog, speeding up the search and data discovery and improving your team’s knowledge about the data held by your company.
-
Data profiling
Datameer excels at data profiling: making it easy for users to analyze, explore, and identify structures and relationships between data sets to make it analytics-ready.
It expresses a visual data profile to users, exposing the shape and contents of the transformed data.

Book a meeting now if you’re interested in harnessing the full capabilities of this easy-to-use, non-technical, no-code collaborative tool.


