DBT and the Challenges of Large-Scale Data Transformation
- Ndz Anthony
- October 5, 2023

As an analyst or data engineer, you’ve just been handed the keys to DBT (Data Build Tool). You’re excited. After all, DBT has been touted as a hero in the realm of data transformations. But as you dive deeper, you start to encounter hurdles that makes you question if DBT is really the right tool for your large-scale data transformation needs.
DBT Overview
DBT, or Data Build Tool, is a development framework that has been making waves in the data transformation space. It combines the power of SQL with the flexibility of software engineering best practices, allowing data analysts and engineers to transform data in their warehouses with ease.
DBT is particularly useful for data modeling, testing, and documentation. It allows users to write transformations as SQL SELECT statements, which makes it easy to understand the transformation logic. But while DBT is a powerful tool, it’s not without its challenges.
DBT’s philosophy is rooted in code. As stated on their website, DBT Labs believes that “code, not graphical user interfaces, is the best abstraction to express complex analytic logic.” This approach, while powerful, can be a barrier for those without deep SQL expertise or Python skills.
In the following sections, we’ll delve into 6 specific challenges that users may encounter when using DBT for large-scale data transformations.
#1: Managing Large Amounts of SQL Code
The first challenge you might encounter is managing large amounts of SQL code. As the complexity and scale of your data transformation tasks increase, so does the amount of SQL code. This can quickly become overwhelming, especially for large teams working on complex projects.
For instance, imagine you’re working on a project that involves transforming data from multiple sources. Each source requires its own set of SQL scripts for data extraction, transformation, and loading (ETL). As the number of sources increases, so does the amount of SQL code you need to manage.
This challenge is further compounded when you consider the need for code reviews, debugging, and version control. Without a robust system in place for managing your SQL code, you could quickly find yourself in a sea of scripts, struggling to keep track of what each one does.
#2: Scaling Data Teams
Scaling a data team is a complex process, and DBT, despite its strengths, doesn’t always make it easier. Here are some of the issues that can arise:
- Collaboration Complexity: As teams grow, so does the code base. It’s unrealistic to expect every team member to be familiar with every line of code. This will often lead to miscommunication, errors, and a slowdown in productivity.
- Quality Control: With a larger team and a more extensive code base, enforcing quality standards becomes a heavy task. The risk of user-reported errors increases, and the overall reliability of your data can suffer.
Consider a scenario where your data team has expanded significantly. You now have a diverse group of data engineers, analysts, and scientists, each contributing to different parts of your data transformations. Coordinating these efforts and maintaining a high standard of quality quickly becomes a challenging endeavor.
#3: Optimizing Data Modeling and Improving Reliability at Scale
When it comes to large-scale data transformations, one of the most significant challenges is optimizing data modeling and improving reliability. As the volume of data grows, so does the complexity of the models. This puts a strain on resources, leading to inefficiencies and potential errors.
The Impact
Manual transformation querying can drain engineering resources, posing a challenge in optimizing data modeling and improving reliability at scale. This can lead to slower data analysis and less accurate reporting, impacting decision-making processes across the organization.
Consider a scenario where your organization is sourcing data from multiple platforms, transformed across over 400 DBT models. The sheer volume of data and the complexity of the models could make it challenging to maintain efficiency and reliability.
The Solution?
While DBT offers some solutions, such as allowing data professionals to build data models using SQL, the challenges of scale remain. As the data continues to grow, so does the need for more robust solutions that handles large-scale data transformations efficiently and reliably.
#4: Data Versioning and History Tracking
Data versioning and history tracking allow data teams to track changes over time, understand the evolution of data, and revert to previous versions when necessary. However, when using DBT for large-scale data transformations, these tasks can become quite challenging.
The Issue at Hand
DBT, while powerful, doesn’t inherently provide robust solutions for data versioning and history tracking. This leads to difficulties in managing changes, tracking the history of your data, and maintaining an accurate record of transformations.
Insights from the Field
Several data professionals have expressed concerns about this issue. For instance, in a Reddit discussion, one user highlighted the challenges of managing “blue/green deployments with tracked versions and rollbacks” in DBT.
The Implications
The implications of this challenge are significant. Without effective data versioning and history tracking, data teams may struggle to maintain accuracy and consistency in their data transformations. This can lead to errors, inefficiencies, and a lack of trust in the data.
Looking Ahead
While DBT does offer some solutions, such as the ability to create snapshots for tracking data changes, the challenges of data versioning and history tracking at scale still remain.
#6: The Rigidity of DBT Testing Rules
DBT’s testing capabilities are a significant part of its appeal. However, when it comes to DBT, the rigidity of its testing rules pose a unique set of challenges.
One of the main challenges is that the rules used in DBT tests are rigid. This rigidity leads to situations where your rules are too strict, and data is incorrectly flagged as invalid, creating false alarms. Conversely, if your rules are too loose, data quality issues can be missed.
My View
From my experience, the rigidity of DBT’s testing rules can be a double-edged sword. On one hand, it ensures a certain level of standardization and consistency in data testing. On the other hand, it can limit the flexibility needed to adapt to different data scenarios and requirements.
Is There a Better DBT Alternative?
You might be wondering, “If DBT has all these challenges, is there a better alternative out there?” Well, I’m glad you asked. Let’s talk about Datameer.
Datameer is like a breath of fresh air in the data transformation space. It’s designed with user-friendliness in mind, making it a great tool for data engineers, analytics engineers, data analysts, and data scientists alike.
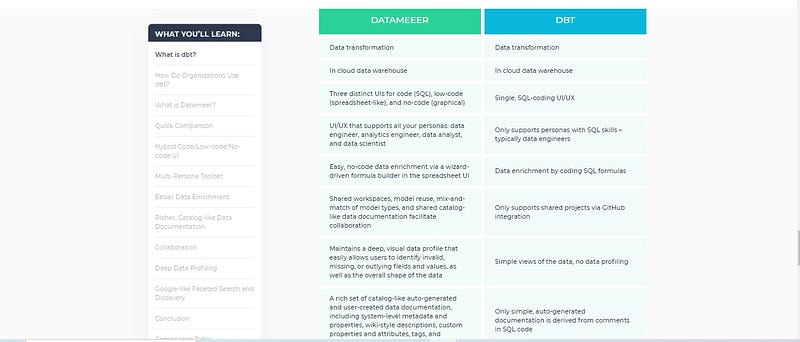
One of the things I love about Datameer is how it addresses many of the challenges we’ve discussed with DBT. For instance, it provides more flexibility in testing rules, which can help avoid those pesky false positives. It also offers robust solutions for data versioning and history tracking, so you can keep track of your transformations without breaking a sweat.
But perhaps the most exciting thing about Datameer is that it’s a powerful no-code alternative to DBT. This means you can focus more on deriving insights from your data and less on wrestling with complex data transformations.
So, if you’re dealing with large-scale data transformations and finding DBT a bit challenging, why not give Datameer a try?


