Datameer X: Data Prep For Machine Learning
- Adam Wealand
- September 16, 2019

We are excited to reveal exciting new features in Datameer. Some new features were long-time requests from our most loyal customers and other new features are on the cutting-edge of data science.
What Is New?
Customers depend on Datameer to transform their raw datasets by formatting, structuring and enriching the datasets for analytic processing and reporting. In addition to data prep, Datameer X is designed for data science. The new features empower users of all levels of technical expertise to speed development of machine learning models and generate trusted, business-ready data insights.
Among its many new features, Datameer X includes complex data science encoding at the press of a button, exploring data at scale with native pivot tables, new production modes that improve performance even more, and Kereberos REST API support for additional security. Furthermore, with the new BigQuery and Hyper format connectors in Datameer X, our customers can easily move their cleaned datasets into the business analytics tool of their choice.
Accelerating The Machine Learning Process
Quality data preparation typically takes more time than any other part of the machine learning process. It is important to get the cleaning and preparation correct because it serves as the foundation for machine learning. With Datameer X you can now apply advanced machine learning encoding at a fraction of the time it previously took the data science team. Reducing the time necessary for data preparation leaves more time to test, tune, and then optimize models. Let’s take a look at all the new turnkey data science encoding capabilities in this release.
One Hot Encoding
Categorical data can’t be used directly with most machine learning algorithms. Datameer’s new One-Hot-Encoding feature effortlessly converts categorical variables into a binary format without ever having to write a line of code.
It is worth repeating…without ever having to write one line of code.
I will briefly dive a little deeper to understand how the data science encoding process, for example one hot encoding, is performed today. At the end, you will not only understand why it is called one hot encoding but also (more importantly) understand why the new Datameer data science encoding features is a major development and a huge gain in data science efficiency.
Quick Dive: What is one hot encoding?
One hot encoding is a data science technique to convert categorical values into a 1-dimensional numerical vector. The resulting vector will equal to 1 and the rest will be 0. The 1 is called “Hot” and the 0’s are “Cold.” This is where “one hot encoding” is derived!
By encoding values, machine learning algorithms perform much better.That is because the algorithms will not misrepresent variables in the model if they are encoded this way. For example, if data with many variables is not one hot encoded, a machine learning algorithm may think that a variable is similar to another variable when they are actually independent of one another.
How is one hot encoding done today?
Data Scientists typically perform their one hot encoding in Python.However it can be tedious and even beginning to do this requires two major hurdles:
1. Knowing how to code in Python and
2. then spending a great deal of time putting data in a Pandas data frame
Even after these, the Data Scientist’s work has just begun. Once the data is in a data frame, the categorical variable must be cast into the Pandas “Categorical” data type. Then, there are even more steps in the Pandas method; converting the categorical variable into dummy/indicator variables, and then more functions, and finally storing the results in a new dataframe….
Or instead of the Pandas method, you or anyone on your team can simply click a button in Datameer X.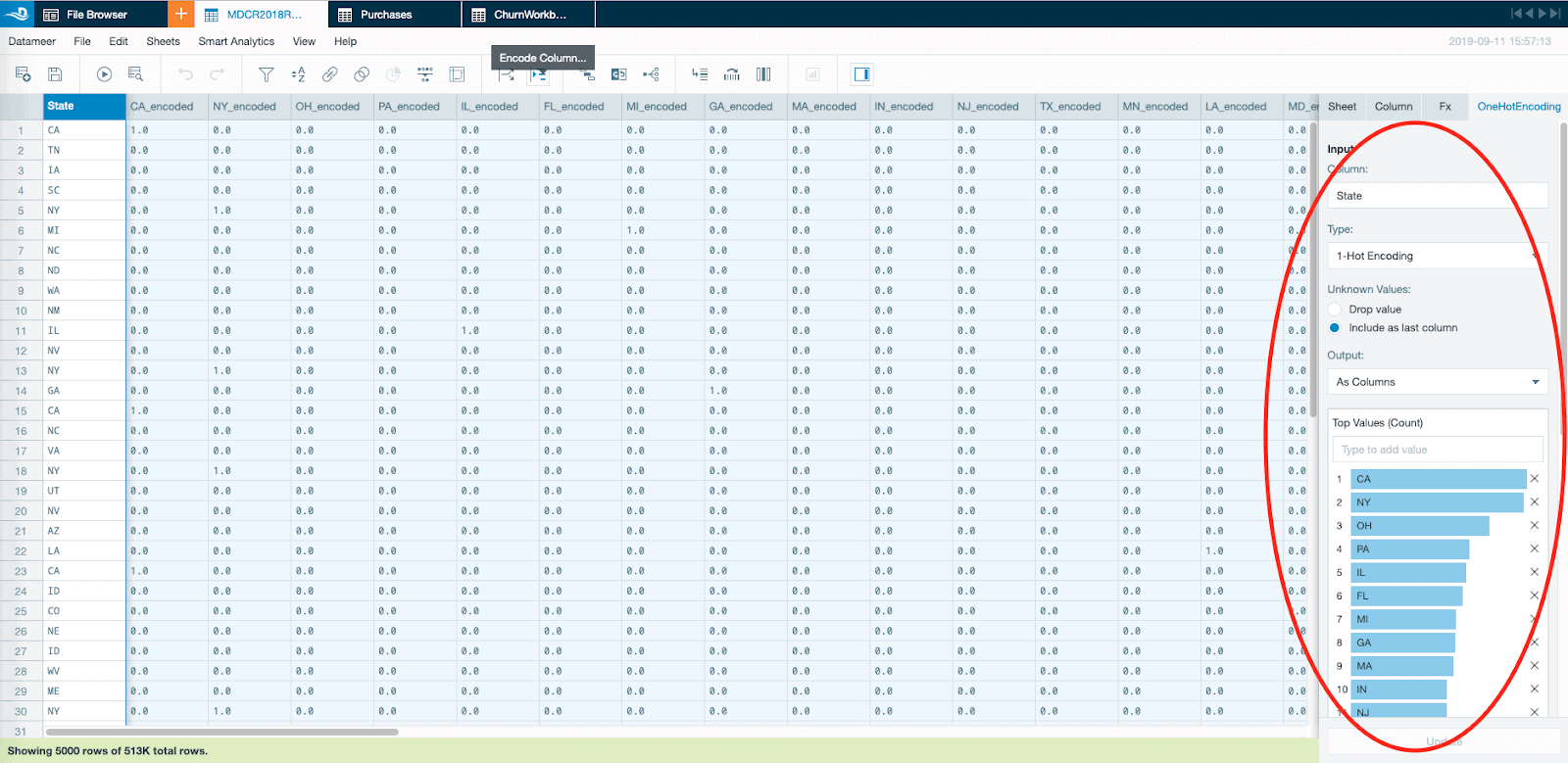
Ordinal Encoding
Effortlessly convert string labels to integer values at the click of a button. Your entire analytics team can enumerate strings and develop models in minutes without ever needing to use Python code and Scikit for preprocessing.
Date and Number Binning For Data Science
Encoding, or generating, new columns from existing dates or numbers in a dataset is a common requirement for machine learning models. This encoding previously required time and expertise in order to write custom code. Datameer now provides a flexible GUI to encode binning specifically for machine learning.
Explore Even More With Native Pivot Tables
Datameer Visual Explorer was the world’s first solution for interactive visual data exploration. Datameer bridges the last mile between analysts and the data lake. With that, we’ve made visual data exploration even more powerful because Datameer X now contains native pivot table functionality.
Pivot tables are incredibly powerful methods to explore data. In Datameer X you can easily scale pivot tables to summarize and segment billions of rows of data across multiple custom defined dimensions to drive discovery with one click in Datameer’s familiar spreadsheet interface. You can expect the same responsiveness in our Pivot Table feature that you see in Visual Explorer, and pivot on billions of rows and hundreds of attributes with response times in seconds.
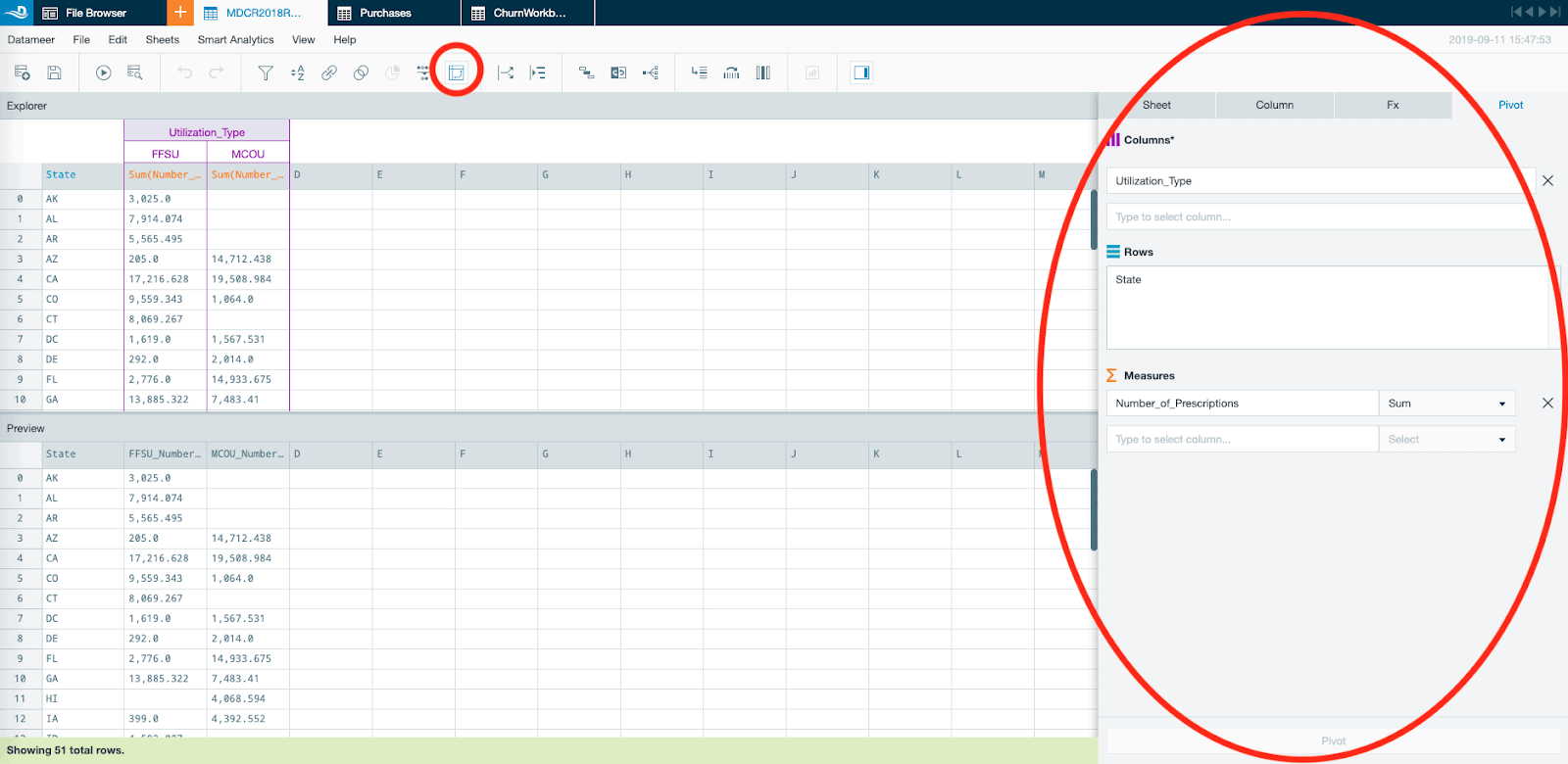
Take a moment to scan through all the new Datameer X features below.
Here is a list of all the new features in Datameer X:
- Data Science Encoding
- One Hot Encoding
- Ordinal Encoding
- Date and Number Binning For Data Science
- Visual Exploration
- Native Pivot Tables
- Operations
- Production Mode
- Workbook Variables
- Open Data Format (early 2020)
- Connectors
- BigQuery
- Tableau Hyper Format
- Security
- Kerberos REST API support


