Data Wrangling for Data Analysis: How Clean Data Can Improve Your Analysis Results
- Ndz Anthony
- January 26, 2023

This article will discuss data wrangling, why it’s essential, and the prevalent differences between data wrangling and analysis.
I remember trying to solve Rubix puzzles in my childhood days. I had no idea how best to reintegrate this cryptic enigma and would sit attempting to for hours on end.
However, with some luck, I always figured it out, and when I did, it called for a ceremony of my gloating and a pat on the head.
What does my story have anything to do with understanding the data-wrangling process ?…
Stick around to find out ☺.
What’s Data Wrangling?
Data wrangling goes by many names- data cleansing, data remediation, or data munging – all refer to a set of methods to convert raw data into more usable representations. The specific strategies vary based on the data you’re using and the aim you’re trying to achieve.
Data munging/wrangling requires a sophisticated understanding of the raw data, the analysis performed, and what information needs to be deleted.
Why is it essential to wrangle data?
The amount of labor that goes into data wrangling is represented by the 80/20 rule in data science and data analysis – stats show that data scientists often spend 80% of their time ‘wrangling’ or preparing data and 20% of their time analyzing the data.
If you don’t run your analysis on good, clean data, your results will be skewed – often to the point where they’ll be more harmful than helpful. Essentially, the better the data you provide for upstream data activities, the more effective the output of your result sets.

Some may question whether the amount of work and time spent on data wrangling is worthwhile.
At this juncture, I’ll take you back to my Rubik’s story, if you don’t mind 😶
A Rubik’s cube only has uniformity, structure, and meaning when it comes together. It took me forever – yeah, no doubt. But the older I got, the more experience I had with this mystery cube, and as a result, the quicker I got.
Similarly, once the code, infrastructure, foundation, and best practices for handling data are in place, data wrangling becomes easier and upstream activities such as data visualization, data science, etc. – become achievable within shorter iterations.
Here are some of the essential characteristics of Data-wrangling:
-
Useable Data:
Data wrangling improves data usability by formatting data for the end user.
-
Aggregation:
It aids in integrating many forms of information and their sources, such as database catalogs, online services, files, etc.
-
Data preparation
Data prep is critical to attaining good outcomes from ML and deep learning initiatives, which is why data munging is vital.
-
Quick decision:
Wrangling the data allows the wrangler to make quick judgments while cleaning, enriching, and transforming the data into an excellent picture.
-
Automation:
Data wrangling techniques such as automated data integration tools clean and transform source data into a standard format that can be utilized repeatedly based on end requirements. This standardized data is used by businesses to undertake critical cross-data set analytics.
-
Saves time:
As stated earlier in this post, data analysts spend most of their time sourcing data from various sources and updating data sets rather than performing fundamental analysis. Data wrangling provides accurate data to analysts promptly.
Difference between Data Wrangling and Data Cleaning
Despite their comparable approaches, data wrangling and data cleaning are independent operations. Upfront data cleansing ensures that downstream processes and analytics receive correct and consistent data, increasing consumer confidence in the information.
Here are some differences between data wrangling and data cleaning:

Dedicated and Best Data Munging Tools For 2023
Knowing their data from front to back is one of the most valuable qualities an intelligent data wrangler can have. You’ll need to understand what is in your data sets, downstream data analysis tools, and end goals.
Historically, most data manipulation was done manually using spreadsheets such as Excel and Google Sheets. It is a viable choice when you have modest data sets that only require a little cleaning and enrichment.
More modern technology is generally preferable when dealing with enormous volumes of data; below, we summarized the Top 6 Best Data Wrangling tools for coders and non-coders:
-
Numpy:
A fundamental package for scientific computing with Python, providing support for large, multi-dimensional arrays and matrices, along with an extensive library of mathematical functions to operate on these arrays.

-
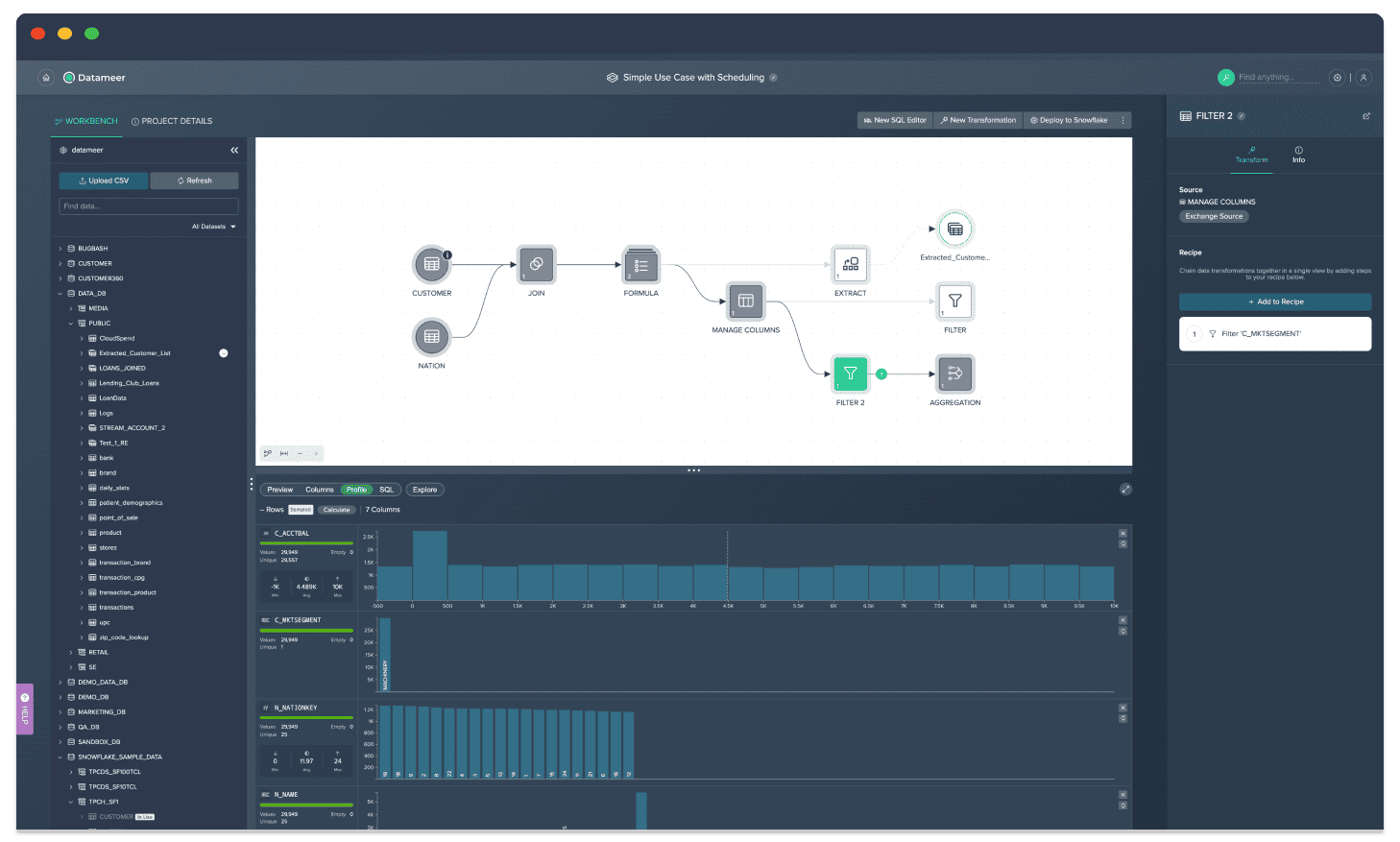
Datameer:
It is a data integration, preparation, and analysis platform that allows users to easily connect to and blend data from various sources and perform data transformations and analysis using a visual, spreadsheet-like interface. It also provides advanced features such as machine learning and predictive modeling capabilities, making it a powerful tool for data wrangling and preparation.
-
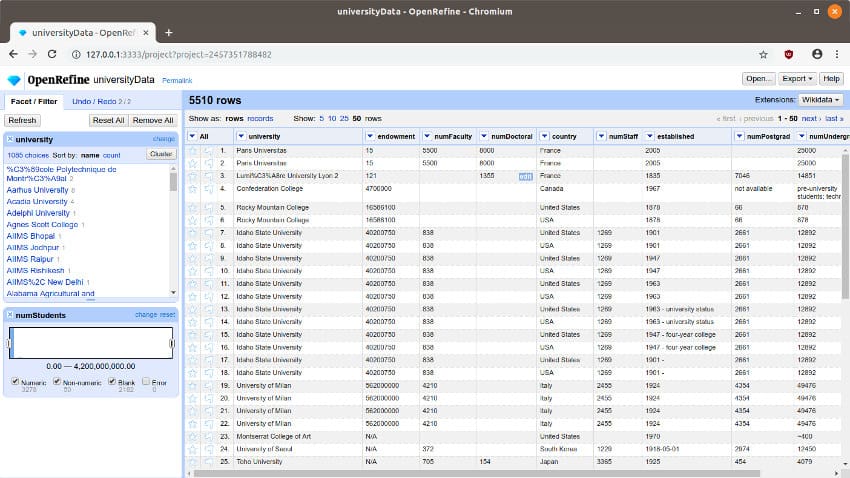
OpenRefine:
A powerful tool for working with messy data, providing a wide range of data cleaning and transformation functionality, including support for regular expressions, clustering, and data reconciliation.
-
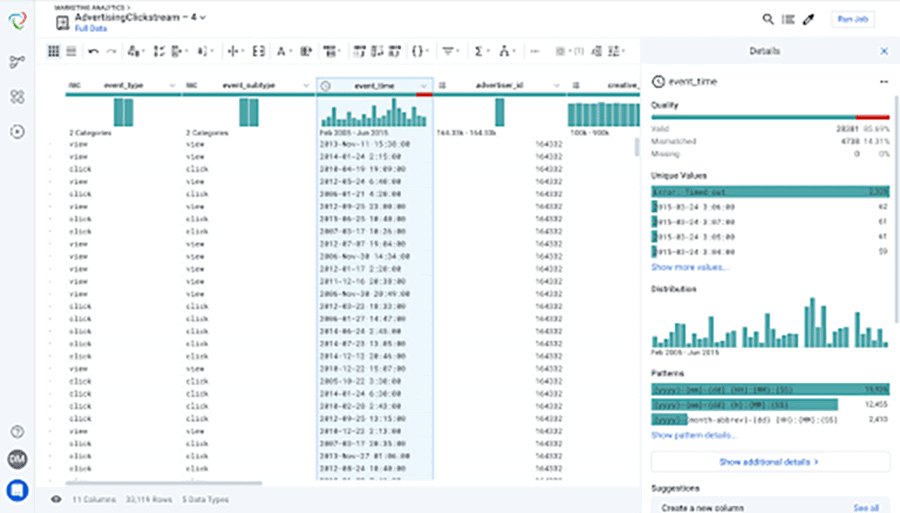
Trifacta:
Allows users to easily clean, shape, and enrich data for analysis and visualization. It provides a user-friendly interface with a wide range of transformation options, including support for regular expressions, data parsing and pivoting, and machine learning-based suggestions for data cleaning.
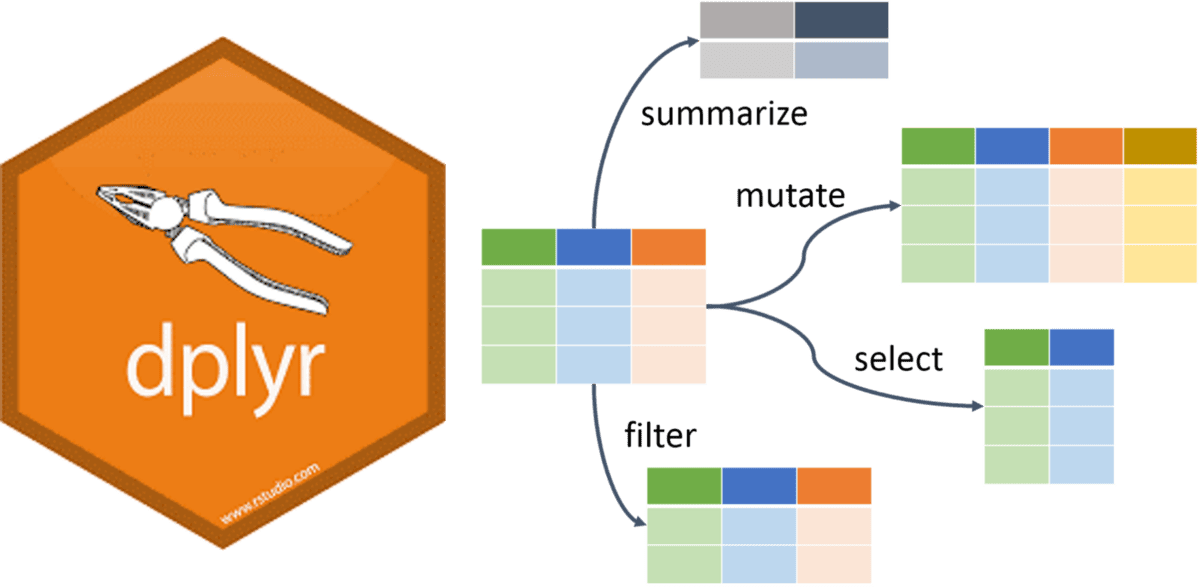
- Dplyr: A powerful data manipulation library for R, providing a grammar of data manipulation for data in data frames, including filtering, aggregation, and transformation.
- Excel: A widely used spreadsheet software that provides essential data manipulation and analysis capabilities through its built-in functions and pivot table features.

Transform your Data with ease using Datameer’s powerful Data-Wrangling capabilities
Datameer is a data integration, preparation, and analysis platform that helps streamline the data-munging process by providing various functionalities.
It allows users to easily connect to and blend data from various sources using a visual, spreadsheet-like interface. Users can perform data transformations, cleaning, and shaping using multiple options such as data parsing and pivoting, support for regular expressions, and machine learning-based suggestions for data cleaning.
It also includes advanced features like machine learning, predictive modeling capabilities, and other analytics functionalities, making it a one-stop solution for data wrangling and preparation.
Given below are the main three reasons why you should choose Datameer over any other tools available in the market:
-
Easy-to-use interface:
Datameer provides a user-friendly interface that allows users to easily connect to and blend data from various sources using a visual, spreadsheet-like interface.
-
Advanced data wrangling capabilities:
Offers a wide range of data munging functionalities, such as data parsing, pivoting, support for regular expressions, and machine learning-based suggestions for data cleaning.
-
Comprehensive analytics capabilities:
Datameer is not just a data wrangling tool but also includes advanced analytics capabilities such as machine learning and predictive modeling, making it a one-stop solution for data wrangling and advanced analytics.
So what are you waiting for?
Stay away from struggling with that cube. Give yourself a backing of advanced technology tools – get started here!


