Data Transformation Optimization : Why Self-Sufficiency Accelerates Insight
- John Morrell
- March 5, 2018

In their original forms, data pipelines were used to enable information flow between structured systems – operational systems, data warehouses, and data marts. The IT departments completely controlled these pipelines. Business analysts and teams would submit requests and, eventually (meaning many months later), they would see the trickle-down of new data. The resulting delays slowed decision-making processes, making this process suitable only for long-running initiatives.
Then along came the data lake and now cloud data warehouses with the promise of using more data and getting results faster. But the complexity of the data and required data teams to remain the gatekeeper. Data teams were able to use new techniques such as agile to speed the process. But, alas, they were still the gatekeepers and, therefore, the bottleneck. The main question facing this next evolution is: How do we remove this bottleneck and free the data to be consumed?
Where’s the Data Transformation Bottleneck?
The typical analytic cycle involves 5 key steps:
- Integration
- Preparation, Curation & Enrichment
- Exploration & Refinement
- Analysis
- Visualization
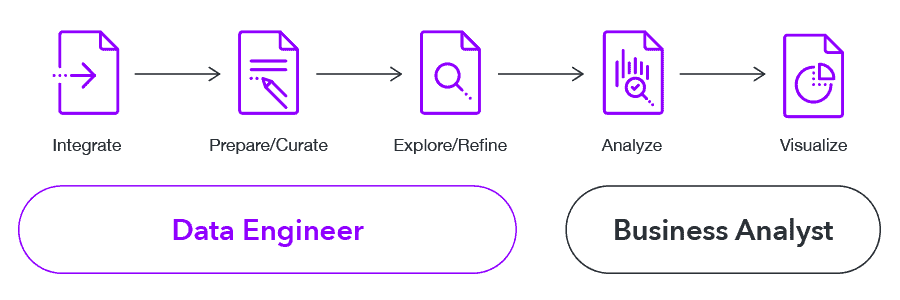
But, as the figure depicts, when the middle stage – exploration and refinement – is separated between different tools, an iterative back-and-forth hand-off can arise, slowing the process:
- First, the data engineer prepares and refines a dataset to the needs of the analyst.
- The analyst then explores and analyzes the data to find it does not reveal the answer and asks the data engineer to try again.
- After a few iterations, the analyst gets a refined dataset that does reveal the answer, finally helping to close the cycle.
This repetitive process of passing the data back and forth to get the proper refinement continues to hinder the analytic cycles, even in the world of data lakes.
There is a Better Data Transformation Approach
There is an often-overused term in the software industry (especially the BI market): self-service. We like to believe we produce software that allows business teams to do their work completely independently without the need for IT. But the reality is that self-service rarely happens.
A faster, more modern approach to data pipelines is a process where data engineers and analysts share responsibility for the end product. We call this a collaborative data transformation process where:
- The data teams do what they do best: ingest, integrate and cleanse data into useable datasets.
- The analyst teams then explore the core data from the data teams further transform it to their analysis’s specific needs and consume this data.
In this case, the business teams become what I like to call “self-sufficient,” meaning the IT teams did just enough to let the business teams finish the job independently. Each group used their unique skill set to do what they do best and work together to speed the creation of a pipeline.
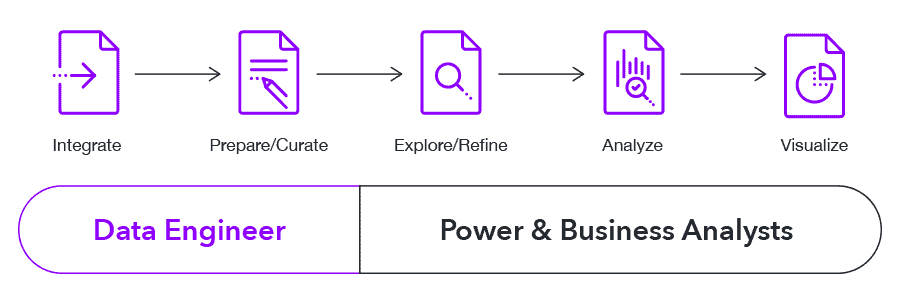
This cooperative process eliminates the last-mile bottlenecks in getting just the right data for the analyst. There are no longer repetitive back and forth exchanges that slow things down, but rather a smooth process, clear responsibilities, and well-defined hand-off points.
What’s the Secret?
The secret to enabling this faster, jointly owned data transformation process is:
- Integrate data refinement into the underlying data transformation tool, eliminating the need to move the data to other tools or locations to refine it
- Offer familiar, easy-to-use metaphors that meet the two audiences’ needs: A data-centric, functional metaphor for the data engineer, and a no-code or low-code metaphor for the analyst, with data shared between the two.
This data transformation process enables analysts to consume data faster, using it when they need it and on their own terms. By enabling self-sufficiency in data transformation, organizations can greatly alleviate process bottlenecks to get to the data they need.
This truly enables an agile process to produce actionable datasets. The business analyst is free to “fail-fast” – explore in any direction, and if they don’t find the answer, back out and try another direction. They fail fast until they get just the right data they need to solve the problem.
Datameer: Collaborative Data Transformation
Datameer is a powerful SaaS data transformation platform that runs in Snowflake – your modern, scalable cloud data warehouse – that combines to provide a highly scalable and flexible environment to transform your data into meaningful analytics. With Datameer, you can:
- Allow your non-technical analytics team members to work with your complex data without the need to write code using Datameer’s no-code and low-code data transformation interfaces,
- Collaborate amongst technical and non-technical team members to build data models and the data transformation flows to fulfill these models, each using their skills and knowledge
- Fully enrich analytics datasets to add even more flavor to your analysis using the diverse array of graphical formulas and functions,
- Generate rich documentation and add user-supplied attributes, comments, tags, and more to share searchable knowledge about your data across the entire analytics community,
- Use the catalog-like documentation features to crowd-source your data governance processes for greater data democratization and data literacy,
- Maintain full audit trails of how data is transformed and used by the community to further enable your governance and compliance processes,
- Deploy and execute data transformation models directly in Snowflake to gain the scalability your need over your large volumes of data while keeping compute and storage costs low.
Learn more about our innovative SaaS data transformation solution by scheduling a personalized demo today!


