Better control over table updates and table locking in Snowflake
- Datameer, Inc.
- June 27, 2021
Let’s explore the workarounds on how to achieve better control over table updates and table locking in Snowflake. Snowflake’s exceptional performance for analytics use cases is partly due to the fact that it is a column-oriented database, versus databases designed for transactional use cases, which are traditionally row-oriented databases.
While Snowflake’s performance for analytical queries is exponentially faster than transactional databases, Snowflake doesn’t perform as well as transactional databases at executing transactions at an individual row level, such as UPDATE, DELETE and MERGE statements. This has to do with the way Snowflake technology is architected at the physical or hardware level, so there is only so much you can do to work around this limitation.
In this article, we will go through three techniques that come in handy for use cases where Snowflake needs to execute transactional workloads that aren’t performing as well as desired. There are ways to work around the limitations in Snowflake, but the workaround depends on the particular use case. If the first technique doesn’t fulfill your requirements, keep reading as these three techniques solve slightly different problems.
Table Clustering
The first workaround or technique is to cluster whatever table you’re trying to update by the key you are updating your records by. For example, if you are updating a customer table with the customer’s status, make sure your table is sorted by a unique or very high cardinality column. When you implement clustering on a table in Snowflake, behind the scenes, your data is sorted and then written to storage in that order. Then all of that data is broken down into clusters, with the minimum and maximum value of each cluster stored as metadata for faster retrieval.
You can think of this as the way a library sorts books by author and then all the books are broken down into smaller groups and placed on several shelves instead of one long shelf. Clustering in Snowflake works the same, but the books are the data in your table, the sort key, “author” in the library case above, is the cluster key, and each bookshelf is a cluster in Snowflake.
Clustering makes it easier to find an individual record if you are looking up a record by sort key. Clustering won’t help in the case where there is not a unique key lookup or multiple records need to be updated at once. This technique only works for particular use cases.
Here are some examples of configuring clustering in Snowflake:
-- cluster by base columns
alter table t1 cluster by (c1, c3);
-- cluster by expressions
alter table t2 cluster by (substring(c2, 5, 15), to_date(c1));
-- cluster by paths in variant columns
alter table t3 cluster by (v:"Data":name::string, v:"Data":id::number)Queued Batch Updates
If a table is being updated frequently enough that Snowflake’s servers can’t keep up, the table might never finish clustering and performance can suffer. If you have high-frequency updates, clustering might not be the right solution for your use case.
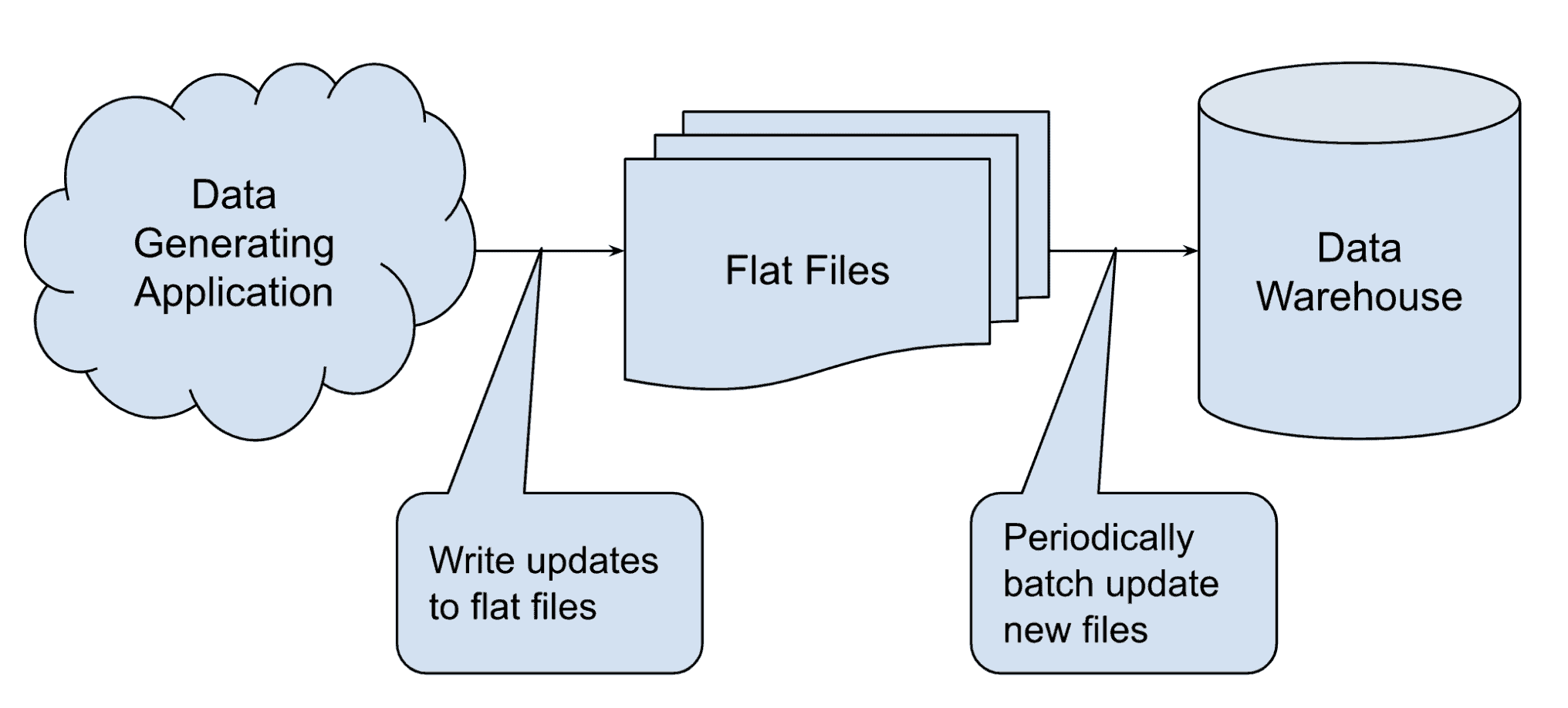
Snowflake is not designed for high-frequency updates, it is designed for large batch updates, meaning one big data file is being loaded all at once, rather than each record being updated one by one. This could be implemented by queuing up all updates/deletes/merges into batches and executing batch jobs at less frequent intervals. The key here is that each interval is less time than it takes for Snowflake to complete each batch update so that Snowflake has enough time to complete each batch. This is generally best practice for data warehouses, which are typically designed to intake large amounts of data.
Here’s a simple diagram of a batch update process:
Staging Tables
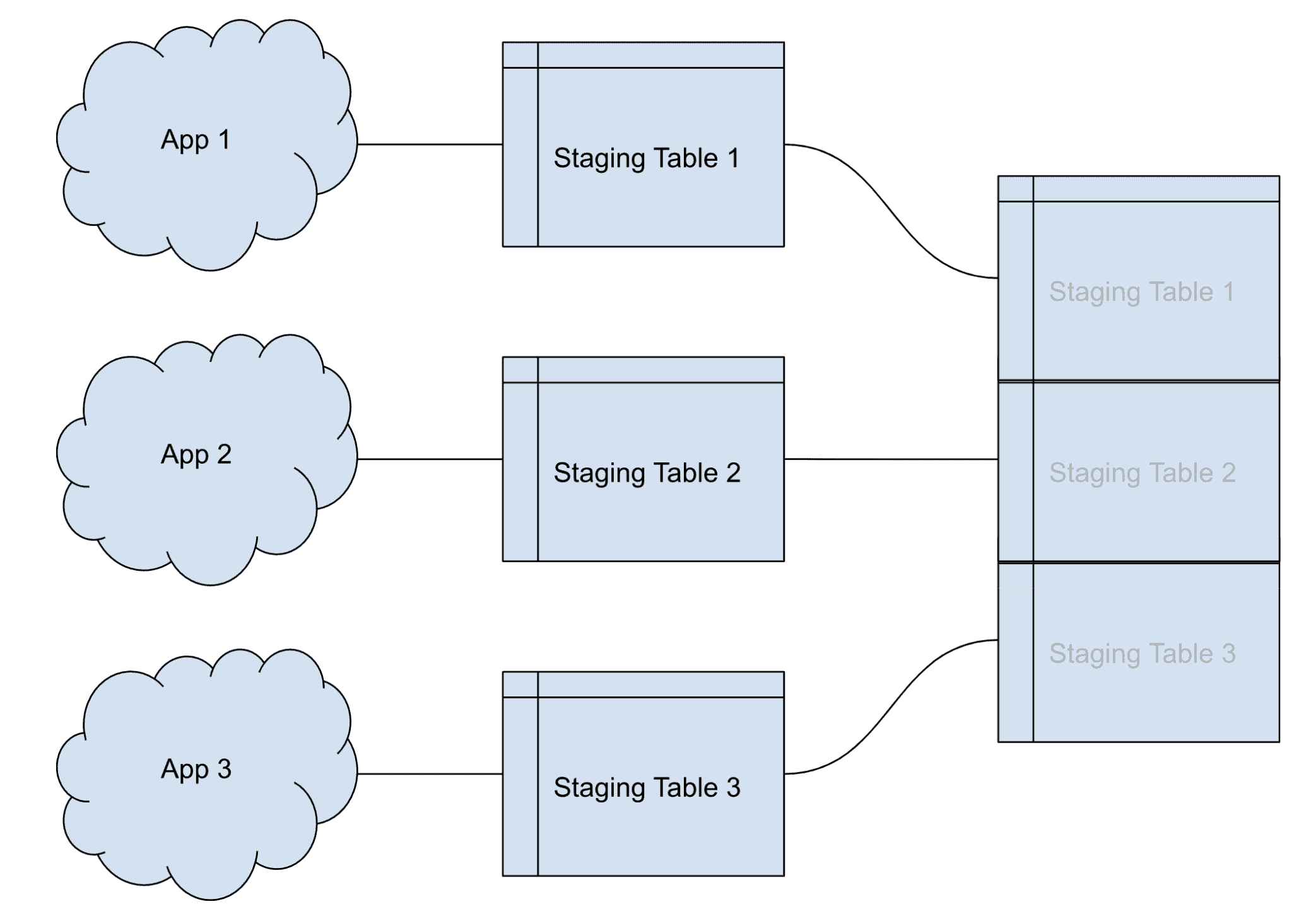
Another common scenario is when several different systems or applications are sending updates and/or merges, which is causing table locks that are blocking updates. This final technique helps handle this use case.
To workaround table locks, create staging tables, one for each system or application, so that each table has one and only one application updating it. This prevents table locks as long as you are also using the batch update technique mentioned above. The final part of this solution involves bringing all these staging tables together into one table or view.
Here’s an example of this solution:
Conclusion
We’ve reviewed three ways to deal with or work around Snowflake’s columnar architecture for transactional use cases, and table updates and table locking in Snowflake. Snowflake is a great tool, but particular use cases or scenarios require creative solutions.
Datameer
As you can tell by the article above, Snowflake can present some fairly complex technology problems. With Datameer, you don’t need to worry about architecting technical solutions like those described above, because best practices for working with data warehouses have already been built into the backend design of Datameer. Datameer allows you to work with your data without worrying about complex technology architecture limitations. Datameer just works, give it a try with the free trial!


