Best Snowflake Features for Continuous Snowflake Data Pipelines
- Jeffrey Agadumo
- December 15, 2022

This article explores the concept of “Snowflake data pipelines.” Simply put, it explains the data pipeline architecture and Snowflake features that assist continuous data pipelines.
Data Pipelines: A Brief History
How did it start?
About 40 years ago, data pipelines began with CPU processing at a hardware level where ‘read, write’ instructions were pipelined together on a silicon board.
These instructions could be fully automated from an end-to-end perspective. You could add to them and take away from them simply and flexibly.
Today, they’ve morphed into more complex building blocks, any processing block moving data from end to end.
All this sounding like gibberish?
Let’s break down the concept of data pipelines.
The Concept of the Data Pipelines

Having a tap is something most of us can relate to; fresh, clean water at the turn of a handle. But I bet the inner workings of how water gets to you are not so easily relatable to everyone.
Source water (like data) is usually found in rivers, springs, lakes , and groundwater, but most of us would dare not drink straight from a lake.
We’d have to treat and transform this water into something safe, and we do this using treatment facilities. We get the water from its primary source to where it needs to go using water pipelines.
When the water has gone from the source to the treatment plant, it’s cleaned and made safe for use and subsequently sent out using even more pipelines to where we need it. And there you have it! Clean water at your disposal whenever you need it.
Of course, this is an oversimplification, but the same concept applies to data pipelines .
Businesses today deal with enormous amounts of data, and to understand it all, they require a single perspective of the complete data collection at the click of a button.
Data is spread across numerous disparate systems and services, which makes it challenging to aggregate it in a way that makes sense for in-depth analysis.
Because there are numerous places along the transfer from one system to another where corruption or bottlenecks (which ultimately create latency) can occur, data flow can be unpredictable.
The challenges widen in extent and severity as the breadth and scope of the data landscape expand.
And that’s precisely why we need Data pipelines .
By doing away with several manual stages, pipelines can enable a seamless, automated data flow from one phase to the next.
Data pipelines are crucial for real-time analytics to assist enterprises in making quicker, data-driven choices.
Data Pipeline Architecture
What’s a data pipeline architecture?
Like our water pipeline example above, the outlay of the water pipes determines which pipe goes to the water fountains, which runs to the home taps, etc.
The design and organization of software and systems that replicate, purge, or change data as necessary before routing it to target systems, is known as a data pipeline architecture.
The specifications for how data is imported and processed within a data warehouse change along with data architectures.
Three factors that contribute to the speed with which data moves through a data pipeline are:
-
The Rate, or throughput:
Rate, or throughput, is how much data a pipeline can process within a set duration of time.
-
Reliability:
For a data pipeline to be reliable, each system inside must be fault-tolerant.
Data quality can be ensured with a dependable data pipeline with built-in auditing, logging, and validation attributes.
-
Latency:
The amount of time it takes for a single data unit to move through the pipeline is known as latency.
Latency relates more to response time than to volume or throughput.
Snowflake – The Modern, Robust Way Of Building Your Data Pipelines.
In the last section, we covered the concept of a data pipeline.
Now, let’s talk about one of the world’s most popular cloud data warehouses; Snowflake.
With over 6,800 customers worldwide, Snowflake offers its users access to a complete network of data instantly, securely, and governed, as well as a primary architecture to support many other types of data tasks, such as creating modern data applications.
How can Snowflake Assist Your Data Pipeline?
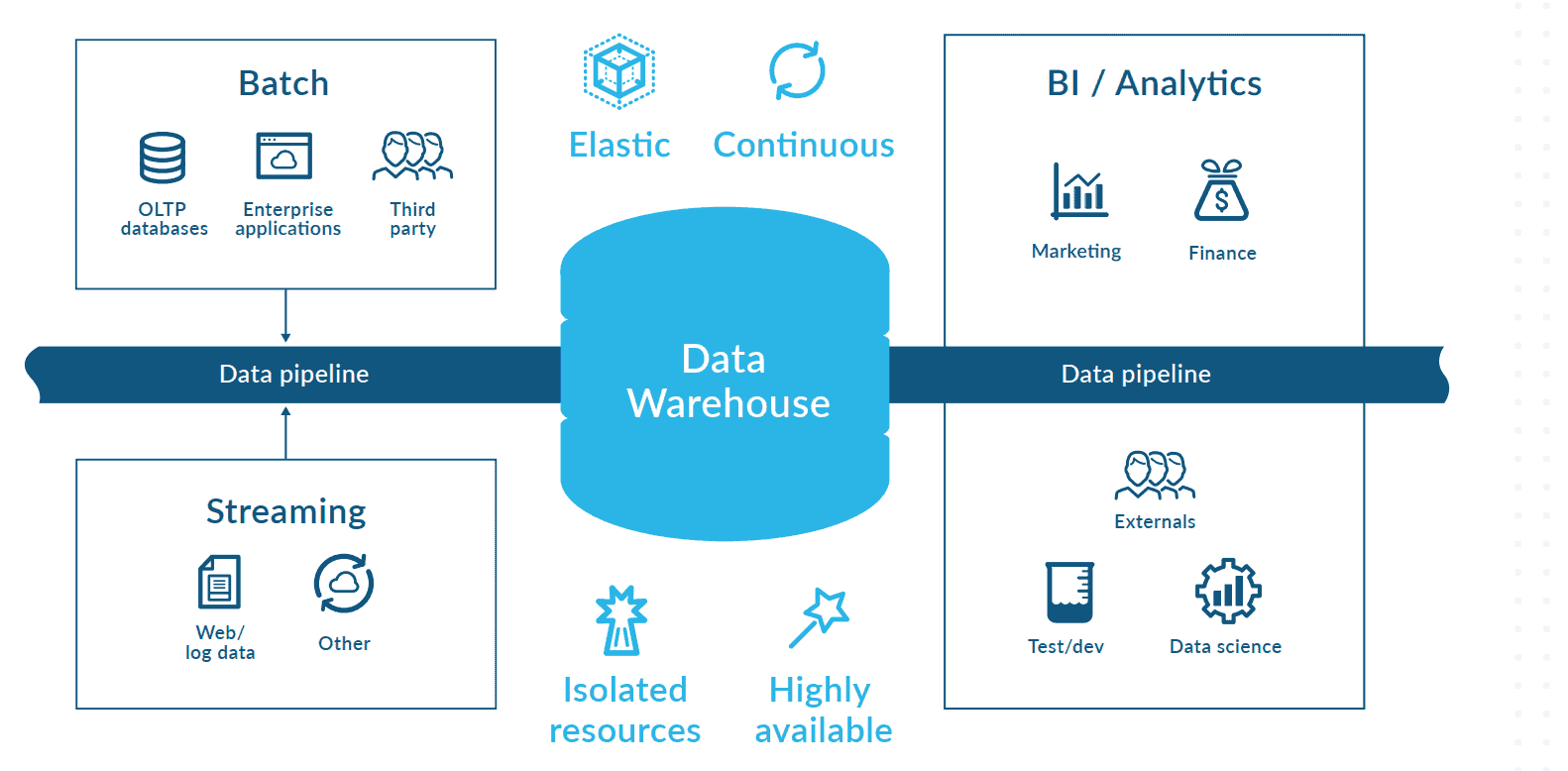
Data-driven organizations need quick, instantaneous access to live data and the capability to evaluate it in real-time to streamline operations, improve customer service, and find new market opportunities.
Snowflake offers a robust, modern way to support batch and continuous data pipelines . Because of Snowflake’s multi-cluster computing strategy, pipelines built with or on Snowflake can handle sophisticated transformations without affecting the performance of other workloads.
Below are a few benefits of building out pipelines within Snowflake.
- Continuous data pipelines : Snowflake provides a simplified way of ingesting and processing data across a broad range of use cases.
Users can continuously move data within a Snowflake environment without the need for scripts or custom code.
- Auto-ingest using Snowpipe : Snowflake users can leverage streaming to continuously load files from Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP) object stores as new data arrives.
Snowflake allows users to parse and insert files using Snowpipe without separate scheduling or orchestration.
- Implementing CDC(Change Data Capture) : With Snowflake, we can capture changes made to our source tables via Snowflake table streams. Change data capture (CDC) use cases allow for continuously loading or changing tables, regardless of the data scale.
- Stream Data from APACHE KAFKA™ : Snowflake offers support for event-driven architectures by ingesting JSON or Avro messages from Kafka via a Snowflake native connector.
Top 5 Best Snowflake Data-Pipeline-as-a-service Tools.
It can take time to select the optimal Snowflake data pipeline tool that fully satisfies your business needs, especially with the wide range of Snowflake ETL solutions in the market.
We put out a post covering the top 6 Snowflake ETL tools so you can narrow your search and quickly start building up or deploying your data pipelines.
Datameer: The T in your ELT Data Pipelines
One of the critical features we mentioned earlier of an exemplary data pipeline is throughput .
Datameer is a cloud analytics stack built for Snowflake that can support and transform your data pipeline/ETL process.
Datameer provides a highly scalable and flexible environment to transform your data into meaningful analytics.
Datameer makes the T–transformation in your ELT data pipelines faster and easier.
Before Datameer, lengthy iterations due to requirements and changes affected the overall data cycle time-to-market lifecycle.
With Datameer, your snowflake experience can be optimized.
Datameer offers:
- A metadata layer into your snowflake environment for the search and discovery of your assets.
- Builds an inventory of assets of all your tables and views.
- Brings in a semantic layer to add descriptions, tags, attributes, etc.
- Data preparation, analysis, and collaboration.
Feel free to check out our webinar on Navigating the Modern Data and Analytics Snowflake Stack with Datacove .


