A Rookie’s Guide to Data Normalization
- Jeffrey Agadumo
- January 30, 2023

Do you need help making sense of your large and clunky tables? Or is managing the relationships between them difficult?
Perhaps, you recently looked at a large and complex database and thought, “What on earth is going on here?” Chances are, the data needed to be normalized.
Normalization is like tidying up your room and putting things in the right place so it’s easier to find them.
Data normalization is ensuring that data is organized and structured in a consistent and meaningful way.
In this article, we will dive into the different types of data normalization and explain why it’s crucial to your organization.
Data Modeling: A Blueprint for Organizing Data
When raw data is collected, a structure of how this data should be stored and organized is modeled . That model is then used to create a schema that arranges data in tables (called relations ) and connects them using keys.
A schema describes the relationships and constraints between different data elements. It serves as a map for storing and accessing data in the database, making it easier to analyze and extract insights.
However, modeling complex data structures can be more complicated depending on the chosen schema and how ideal it is for your dataset.
What is Data Normalization?
Data normalization is analyzing and organizing tables to ensure that they are well formed – meaning they have minimal duplicates and maintain functional dependencies between one another.
It involves dividing larger tables into smaller, more manageable ones and properly defining relationships between them.
A database that hasn’t been normalized is highly prone to anomalies such as:
- Insertion Anomalies : When a row of data is not entered into a table because it is missing one or more required fields.
- Update Anomalies : When a table contains multiple instances of a piece of data and only one or more of those instances are updated, leaving the rest unchanged.
- Deletion Anomalies : When a field of unwanted data can’t be deleted from a table without deleting that entire data record.
Why Should We Normalize Data?
Normalization is an important process that is sometimes misunderstood and avoided. However, normalizing your data provides several benefits, such as:
- Data Integrity : Normalization helps to ensure that stored data is coherent and accurate, improving the data’s integrity.
- Data Consistency : Normalization ensures that data is stored in a consistent format across your entire database, making it easier to understand and use.
- Reduced Data Redundancy : By breaking data down into smaller, more manageable tables, normalization helps to reduce the amount of redundant data that take up storage.
- Improved Data Access : Normalization makes accessing and retrieving specific data easier by creating a clear and logical structure for the data.
Data Normalization Ruleset
How can analysts detect and correct anomalies that occur in a database? Or, how do they determine if a database is normalized correctly?
When an anomaly is detected in your database, rules exist that help you ensure it is stored in its normal form .
These rules provide a framework for analyzing the keys for each table and creating dependencies between them to reduce the risk of anomalies.
Think of each as a checklist of requirements you must apply to normalize your data.
In the checklist, we have the following:
First Normal Form (1NF)
Being the first, this normalization form serves as the baseline of the other forms and must be checked off first.
This form primarily focuses on atomic values and unique identifiers in a table.
For a database to be in its first normal form, each table must meet the following rules;
- Have a primary key.
- Have no repeating groups
- Have a single and unique value in each table’s cell.
Note: The tables below highlight a data normalization use case, Taking you from the unnormalized form (UNF) to the third norm
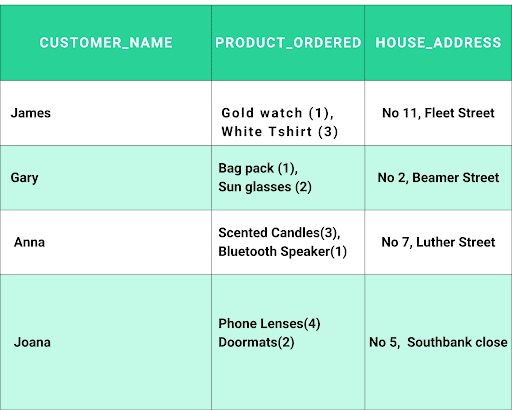
Before 1NF: Ordered Products (Unnormalized form)
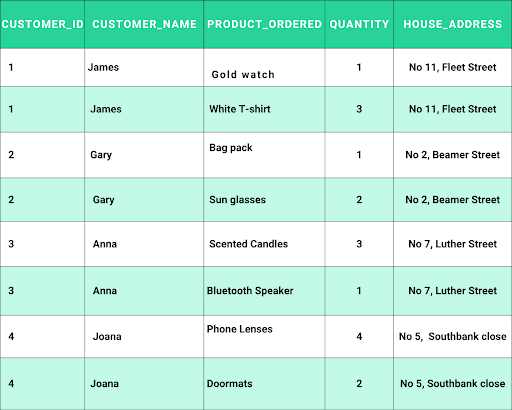
Table After 1NF: All repeating values are separated with primary keys (Customer_id and product_ordered).
Second Normal Form (2NF)
When the database meets the requirements of 1NF, the second normal form (2NF) checks for functional dependency between all the attributes (columns) of a table and the primary key column(s).
A database meets the second normal form when it meets the rules listed below:
- Meets 1NF.
- All attributes in a table must depend totally on the primary key(s), and there must be no partial dependency of any column on the primary key.
This means that any non-primary key column must depend on the entire primary key and not just a part of it.
The above table does not meet the second normal form because the ‘house_ address’ and ‘quantity’ columns only have partial dependencies with the primary keys.
The second Normal Form will divide this table into two (Customer Information and Ordered Products)
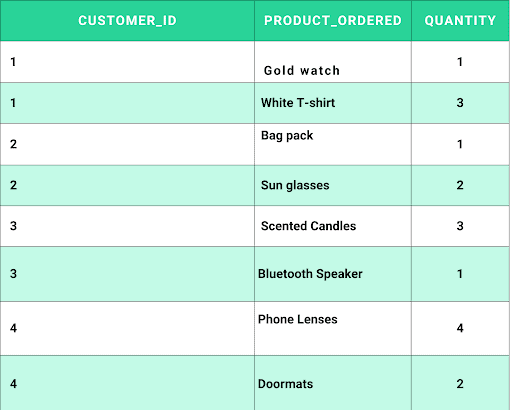
After 2NF: Ordered Products
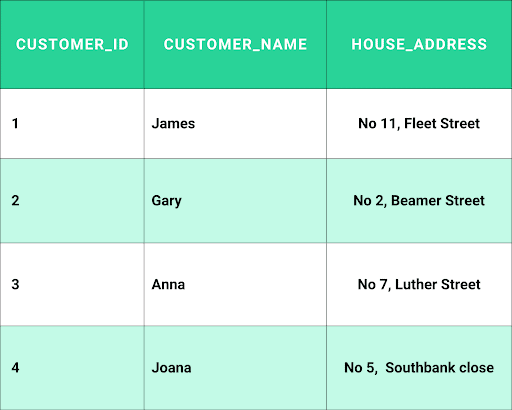
After 2NF: Ordered Products
Third Normal Form
The third Normal Form (3NF) is a database normalization rule that states that a table should not contain any non-primary key columns dependent on other non-primary key columns.
In other words, all non-primary key columns in a table should be directly dependent on the primary key and not on any other non-primary key columns. This helps to eliminate data redundancy and improve data integrity.
To achieve 3NF, a table must:
- meet the requirements of the First Normal Form (1NF) and Second Normal Form (2NF).
- There should not be any transitive dependencies (A -> B -> C) where A is not a primary key and B is not a primary key, but C is dependent on both A and B.
- Eliminate columns that do not depend on the key.
The Ordered products table above does not meet the third normal form because the quantity column has a transitive dependency on the primary key.
The table will be further normalized.
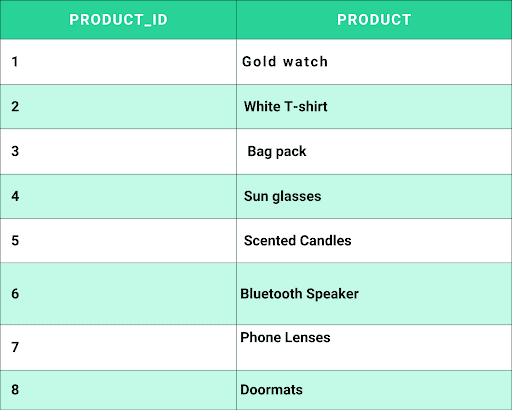
After 3NF: Product Information
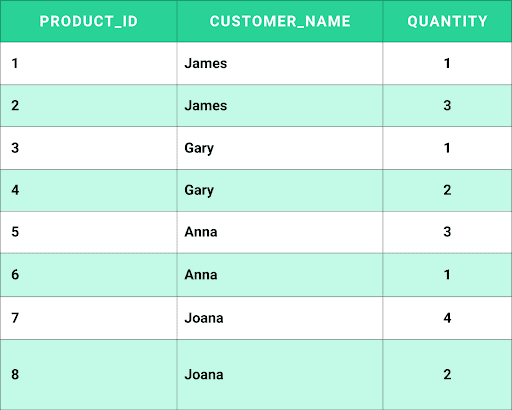
After 3NF: Ordered Products
Data Normalization Limitations
Normalizing a database can make it more efficient, improve data integrity, and make it easier to maintain and update.
However, it is essential to note that data normalization is mainly suited for write-intensive (frequently updated) databases that are smaller and without overly complex relationships.
It can often lead to issues like:
- Increased Complexity: Normalization can result in a complex database design with multiple tables and relationships, making it more difficult to understand and maintain.
- Performance Issues: Too many separate tables can lead to performance issues, such as an increased number of joins, which can slow down queries.
- Data Duplication: Normalization can lead to duplication, as the same data may be stored in multiple tables. And this can make it difficult to ensure data consistency and integrity.
- Reduced Flexibility: Normalization can lead to a lack of flexibility in the data model, as changes to the data may require changes to multiple tables.
To avoid these issues, you must denormalize.
Denormalization: An Antithesis
The question of when to denormalize a database comes down to balancing data integrity and database performance.
What is denormalization, you say?
Denormalization is adding redundant data to a database to improve query performance. Denormalized data is typically stored in a single table with multiple copies of the same data rather than spread across multiple related tables.
This can make it faster to retrieve data, but it can also lead to data inconsistencies and increased storage space usage.
Denormalization is typically used when query performance is critical, such as in data warehousing and business intelligence applications, where large quantities of data need to be analyzed quickly.
In such scenarios, the benefits of denormalization outweigh the potential drawbacks.
Normalization vs. No Code
Datameer is a data integration platform that helps normalize data by providing a range of tools and features for data preparation and transformation.
It gives your data a makeover so it’s ready for analysis. Datameer has a bunch of features to help you do this:
- Data Profiling: Datameer provides data profiling capabilities that allow you to understand the structure and quality of your data, so you can identify any issues that need to be addressed.
- Data Transformation: Datameer allows you to transform data using a variety of functions, such as converting data types, renaming columns, and splitting data into multiple columns.
- Data Validation: Datameer allows you to validate data using a set of built-in validation rules or custom validation logic.
- Data Integration: Datameer allows you to integrate data from various sources, including structured and unstructured data, and normalize it for analysis and reporting.
- Data Governance: Datameer has robust data governance features that enable you to manage and monitor data quality, lineage, and compliance in a collaborative environment.
Best of all! You get all these at the tip of your fingers with No SQL code.
Unlock the full potential of your data today with our cutting-edge no-code environment and transformation techniques.
From accuracy to consistency, our features guarantee that your data is ready for analysis and decision-making in real time.


