The Easiest Way to Split Large JSON Files in Snowflake
- How-Tos FAQs
- September 19, 2020

I’ve been working in data engineering for nine years. I’ve used several on-premises and cloud databases from Oracle, Google, Amazon, Microsoft, etc. I’ve also happily used open-source solutions such as PostgreSQL and MariaDB, among others. However, three years ago, and after much thought, my team decided to adopt Snowflake as our data warehouse. And, we’ve never looked back since. It has been an absolute pleasure to use its revolutionary features at blazing-fast speeds. My top three favorite features would easily be “Zero Copy” clones, “Time-travel,” and native-support for semi-structured datasets.
After completing three end-to-end Snowflake Data migration projects, I’ve come to realize, the best way to extract data from legacy databases is by way of schema-less JSON files. From a scalability point of view, it excels compared to CSV file format and helps to minimize engineering impact. Any drawbacks associated with additional storage requirements for JSON, in comparison to CSV, are easily outweighed by JSON’s scalability.
Typically, a legacy database migrating into the cloud has accumulated a large amount of data in tables. Aside from keys and indexes, this data could be well within the range of millions to billions of records amounting to GBs/TBs, respectively.
Snowflake’s optimum file size is somewhere between 100, and 250 MB compressed. The small file size presents a strict limitation when loading data from large JSON files into Snowflake, and I’ve seen many customers struggle with this.
With this tech challenge in mind, I’ve developed a simple solution that could solve this in a single statement on the command line. It doesn’t involve writing any SQL to handle data splits at the source database end.
I’m taking a relatively large JSON dataset that I found on Kaggle, very kindly open-sourced by Yelp. More details on the dataset can be found here. In particular, we’re looking at the “yelp_academic_dataset_user.json” file of size 3.6 GB. For the curious minds, the schema of the dataset looks like so:
{
"user_id":"q_QQ5kBBwlCcbL1s4NVK3g"
"name":"Jane"
"review_count":1220
"yelping_since":"2005-03-14 20:26:35"
"useful":15038
"funny":10030
"cool":11291
"elite":"2006,2007,2008,2009,2010,2011,2012,2013,2014"
"friends":NULL
}Go ahead and download the dataset now, if you haven’t already.
With that done, lets now split this large file (screenshots to be attached here):
- Open a bash terminal. I generally use VSCode and open a git bash terminal.

- Next, go to the directory where you downloaded the dataset. Post which from bash, run the following code:
cat yelp_academic_dataset_user.json | split -C 500000000 -d -a4 - yelp --filter='gzip > $FILE.gz' - Understand the command:
-
cat: Reads data from a file and displays output to console yelp_academic_dataset_user.json: Large file we wish to split split: as the name suggests -C 500000000: number of records to split by -d: adds a numeric suffix to the end of output file name -a4: 4 digit numeric suffix (default is 2) -: lonely hyphen binds the current command to the previous cat command yelp: output file name that gets attached to the numeric suffix --filter: compresses the file via gzip. Standard compression in Snowflake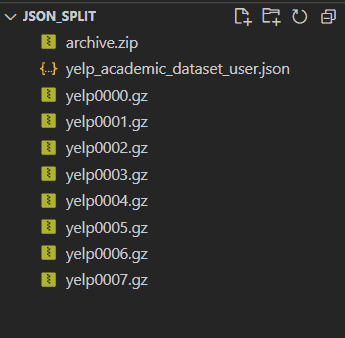
- Putting it all together, we’re splitting a file every 500 million records, adding a file name prefix and suffix, and compressing the output file on the fly.
- It is also worthy to note that Snowflake will automatically compress the file before storing it if you remove the compression and push it into Snowflake.
- The entire file split process took less than 5 minutes for me.
On another note, this simple CLI-based file splitter works on both JSON and CSV.
So there you have it, a simple command-line “file split” statement that splits large JSON files easily.
Up Next:
Learn more about the SQL Window Functions and Common Errors


