Handling Semi-Structured Data in Snowflake
- How-Tos FAQs
- September 13, 2020

With the advent of big data and IoT, there has been a proliferation of semi-structured datasets in the form of JSON, Avro, Parquet, Orc, XML, etc. It is no wonder that Snowflake has paid special attention to these data formats and provided an intuitive and easy approach to handle the same. Also, it is important to mention that Snowflake, unlike many other traditional and cloud-based data warehouses, handles semi-structured data natively within its ecosystem. The best part is, it handles semi-structured data using SQL.
Please note, we are considering JSON as our preferred choice of semi-structured data; however, the principles we learn and the examples we encounter apply to other data formats as well.
With that said, let’s get started, by creating our first data set, ‘organisations.json’, as below:
{
"data": "organisations",
"insert_date": "2021-09-13",
"organisations": [
{
"name": "Facebook",
"org_code": "111222330",
"hq_address": "Menlo Park, California"
},
{
"name": "Apple",
"org_code": "111222331",
"hq_address": "Cupertino, California"
},
{
"name": "Amazon",
"org_code": "111222332",
"hq_address": "Seattle, Washington"
},
{
"name": "Netflix",
"org_code": "111222333",
"hq_address": "Los Gatos, California"
},
{
"name": "Google",
"org_code": "111222334",
"hq_address": "Mountain View, California"
}
]
}Now, we need to create a table to store our raw data:
CREATE OR REPLACE TABLE TEST_1.PUBLIC.orgs
(
json_data VARIANT
);The ‘Variant’ data type is a Snowflake special data type that helps to handle semi-structured datasets as described earlier. More details on this can be found here .
Now, navigate to the data loading tab within Snowflake’s Web UI and click on ‘Load Table’:
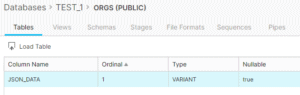
Choose the appropriate warehouse and click ‘Next’:
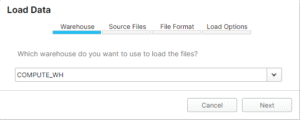
Now, browse to our earlier created Json file ‘organisations.json’ and click ‘Next’
Now, be sure to use an existing file format of type=Json or create a new one as below:
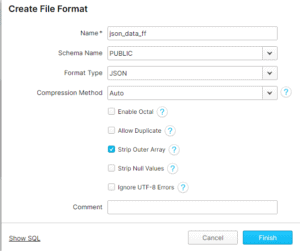
Finally, be sure to select the following option as below to ensure no bad records enter:
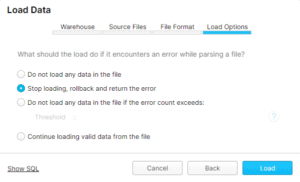
The above images will help to load data into Snowflake without any issues. However, if your JSON is over 50 MB compressed, the WebUI method of loading data is not a best practice.
Hence, alternatively, through SnowSQL or Python, or another scripting language, you might want to run the following SQL command:
PUT file://<file_path>/organisations.json @ORGS/ui1631538145241
COPY INTO "TEST_1"."PUBLIC"."ORGS" FROM @/ui1631538145241 FILE_FORMAT = '"TEST_1"."PUBLIC"."JSON_DATA_FF"' ON_ERROR = 'ABORT_STATEMENT';Finally, run a simple SELECT * to get the following output:

Or the same as we have created within our text file earlier.
The first step is to explore the data as below:
SELECT json_data:data,
json_data:insert_date,
json_data:organisations
FROM TEST_1.PUBLIC.orgs;
Using native variant features, we can query the variant column using colon notation. The colon helps to enter the first hierarchy within this JSON.
The double-colon helps to assign Snowflake data types to structured columns.
SELECT json_data:data::STRING,
json_data:insert_date::DATE,
json_data:organisations
FROM TEST_1.PUBLIC.orgs;
An alternative to the above is to use the JSON parsing function in Snowflake, as below:
SELECT parse_json($1):data::STRING,
parse_json($1):insert_date::DATE,
parse_json($1):organisations
FROM TEST_1.PUBLIC.orgs;Using this method, you should get the same output as the previous statement.
Now, let’s enter the next level of hierarchy:
SELECT json_data:data::STRING,
json_data:insert_date::DATE,
value:hq_address::STRING,
value:name::STRING,
value:org_code::NUMBER
FROM TEST_1.PUBLIC.orgs,
LATERAL FLATTEN( input => json_data:organisations);
You may recognize the first two columns derived in the same manner as this post before this section. However, in the last three columns, you’ll notice we have entered the next level of hierarchy.
To do this, we first join our table TEST_1.PUBLIC.orgs with the LATERAL FLATTEN function wherein we input only the next hierarchy level or json_data:organisations. Essentially, the LF (Lateral Flatten) function here works to remove the hierarchical nature of JSON and convert it into a structural format, thereby creating redundant values in the columns, as can be seen in the above output.
Also, notice here that ‘json_data’ is the variant column we have created, and organizations are the second level of hierarchy in it.
The output of this join is called ‘value’, which is used in the SELECT clause of the query to extract and view the choice of columns in our second level of hierarchy.
Finally, we can use this query to create a sample target table and load the structured data into it as below:
CREATE OR REPLACE TABLE TEST_1.PUBLIC.target_structured_orgs AS
SELECT json_data:data::STRING as Data,
json_data:insert_date::DATE as Insert_Date,
value:hq_address::STRING as HQ_Address,
value:name::STRING as Name,
value:org_code::NUMBER as Org_Code
FROM TEST_1.PUBLIC.orgs,
LATERAL FLATTEN( input => json_data:organisations);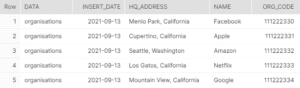
Naturally, the next question that comes to your mind is, what happens when we have several nested hierarchies?
Let’s create some sample data and load the same as we had done above:
{
"data": "organisations",
"insert_date": "2021-09-13",
"organisations": [
{
"name": "Facebook",
"org_code": "111222330",
"hq_address": "Menlo Park, California",
"products": [
{
"model":"2010",
"patented":"Yes"
}
]
},
{
"name": "Apple",
"org_code": "111222331",
"hq_address": "Cupertino, California",
"products": [
{
"model":"2005",
"patented":"Yes"
}
]
},
{
"name": "Amazon",
"org_code": "111222332",
"hq_address": "Seattle, Washington",
"products": [
{
"model":"2000",
"patented":"No"
}
]
},
{
"name": "Netflix",
"org_code": "111222333",
"hq_address": "Los Gatos, California",
"products": [
{
"model":"2010",
"patented":"No"
}
]
},
{
"name": "Google",
"org_code": "111222334",
"hq_address": "Mountain View, California",
"products": [
{
"model":"2012",
"patented":"Yes"
}
]
}
],
"location": [
{
"continent":"North America",
"country":"United States of America"
}
]
}First, let’s create our staging table:
CREATE OR REPLACE TABLE TEST_1.PUBLIC.multi_hierarchy_orgs
(
json_data VARIANT
);This is how the data should look like in our staging table:
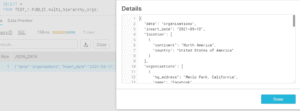
Now, taking all of our learnings to create a query that services all hierarchies.
SELECT
json_data:organisations,
v1.value:name::String,
v1.value:hq_address::String,
v1.value:org_code::String,
v2.value:model::String,
json_data:location,
v3.value:continent::String
FROM
multi_hierarchy_orgs
--Nesting Level 1: Organisations
, lateral flatten( input => json_data:organisations ) as v1
--Nesting Level 2: Products
, lateral flatten( input => v1.value:products ) as v2
--Nesting Level 2: Locations
, lateral flatten( input => json_data:location ) as v3;This should give us the following output:

Using various native Snowflake features such as Lateral Flatten, parse_json, and colon notations, we can easily and intuitively handle semi-structured data in Snowflake.
Up Next:
Learn how to Get Snowflake Results in Pandas DataFrame


