What is Data Enrichment?
Data enrichment is a crucial step in preparing data for analytics, providing additional information and context for more meaningful insights. It has evolved over the past decade, with various approaches to adding new fields and data to datasets, depending on the original data and data source, and there are tools available to streamline the process for faster and easier enrichment.

Data Enrichment Defined
Data enrichment refers to the process of appending or otherwise enhancing collected data with relevant context obtained from additional sources. This enrichment can be performed by adding new calculated fields, integrating disparate data from other internal systems, or appending third-party data from external sources.
Enriched data is a valuable asset for any organization because it becomes more useful and insightful. A simple form of data enrichment is to add new fields that are derived from the existing data. Another common form of data enrichment is in customer or marketing analytics, where additional information about customers and marketing actions is added to see what was successful and what was not. This technique can also be used in other analytics, such as operational analytics.
Data Cleansing versus Data Enrichment
Data cleansing is the process of detecting and/or removing corrupt or inaccurate records from a set of data. With data cleansing, you can identify data that is incomplete, incorrect, inaccurate, or irrelevant, and apply functions and/or algorithms to address these issues with the data.
Data cleansing is related to data enrichment in that in both processes, the data is being improved. However, with data cleansing, you are fixing the data, while with data enrichment, you are enhancing the data .
Use Case Examples
The most common use case example for data enrichment is adding demographic data that comes from other internal systems or external (3 rd party) sources to customer data. Specific examples include:
- Marketing – adding data from any number of sources to better refine marketing campaigns and processes for better targeting and offers.
- Lending – using third-party databases which help them develop a more complete profile of their customers to help with credit scores or underwriting.
- Insurance – add as much data as possible (both internal and third-party) to enrich data for customer categorization, segmentation, and targeting.
- Retail – adding data to better profile and recognize customer needs for recommendations, upselling, and cross-selling.
Data Enrichment Approaches
There are multiple ways data can be enriched, including appending data, segmentation, deriving attributes, imputation, entity extraction, and categorization. Let’s explore how Datameer can help you with each.
Appending Data
By appending data, you bring multiple data sources together to create a more holistic data set than any one data source. This helps you generate more accurate analytics or explore more variables to use as features to improve machine learning models. Appended data can be both internal and external data.
Datameer provides two features that make it easy for anyone (programmer or non-programmer) to append data:
- The ability to upload and use files inside data flows from various formats (Excel, CSV, JSON) that contain data from internal or external sources without the need to write SQL DDL and import processes, and
- A no-code data blending operation that recommends blending options to make it easy to append different datasets together without the need to write complex SQL JOIN and UNION code.
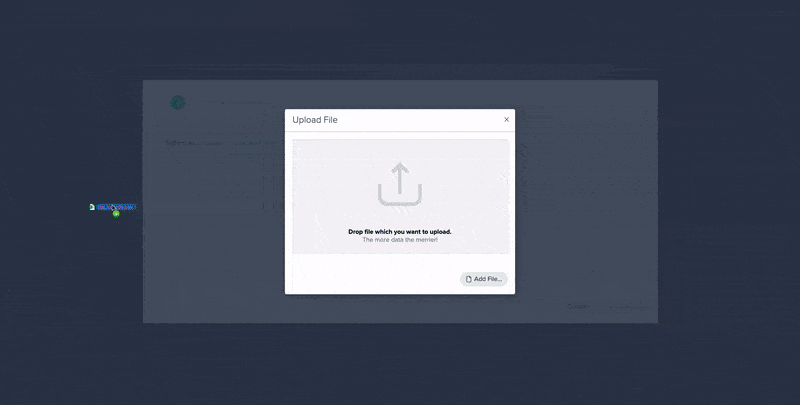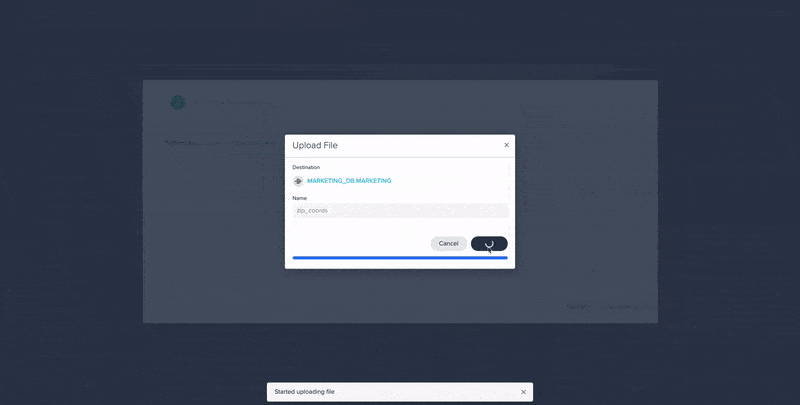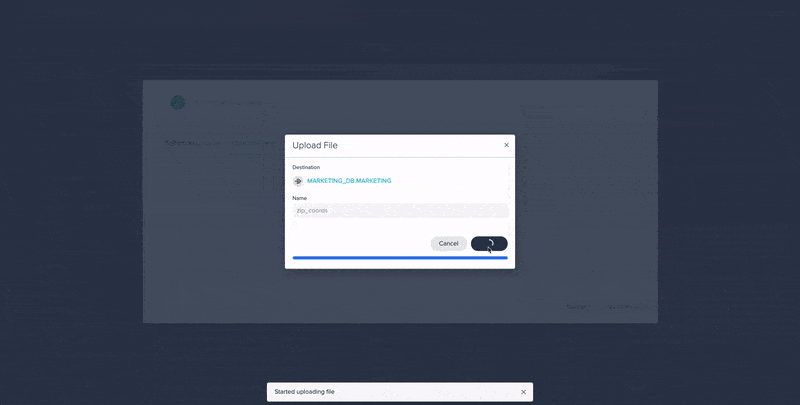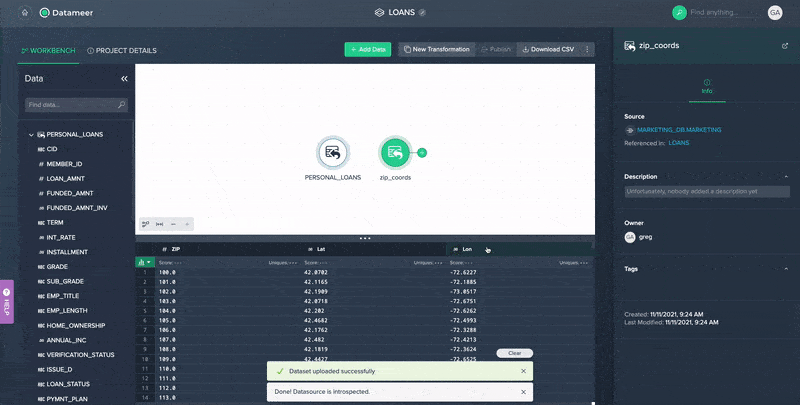
File Upload to Enrich Data in Datameer
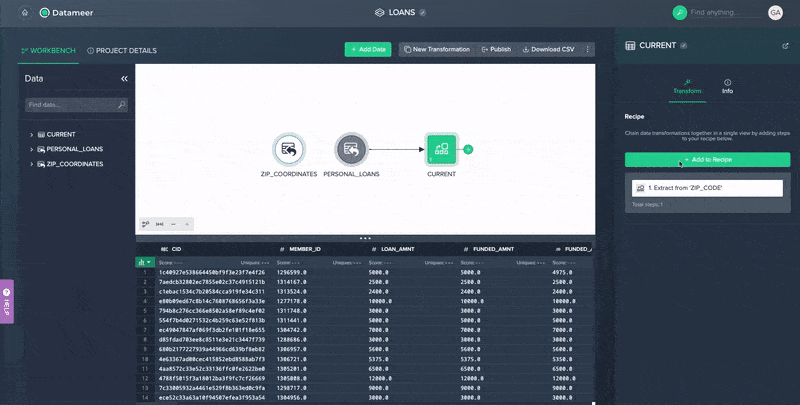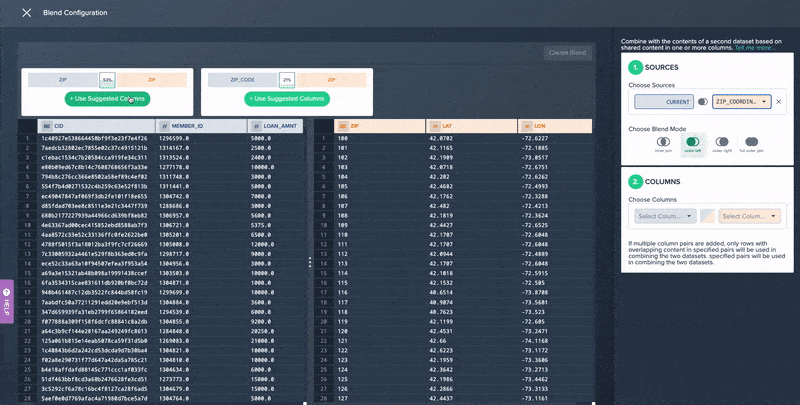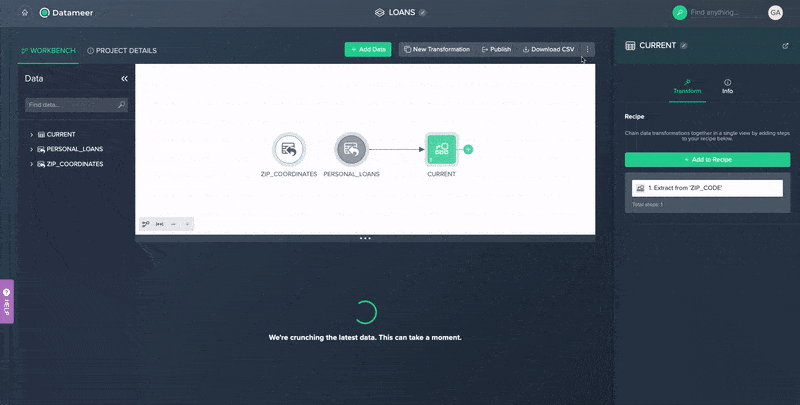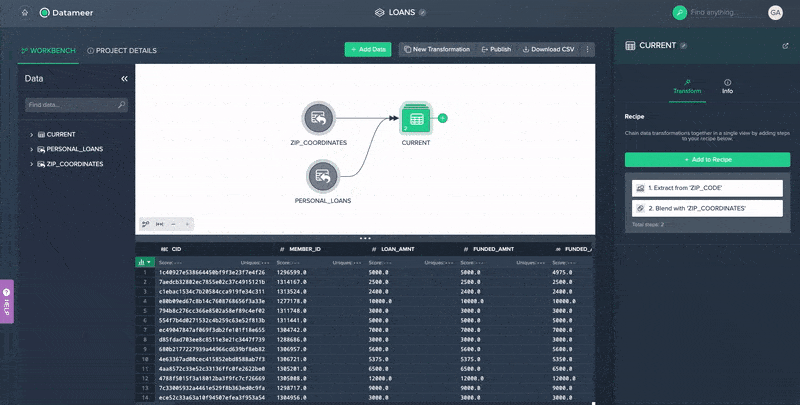
No-code Data Blending in Datameer
Segmentation
Data segmentation allows you to divide or organize a dataset according to specific field values in the data. Very common segmentation is done using demographic, geographic, technology, or behavior values. This is often used in marketing use cases for targeting.
The first step in segmentation is typically to append data, which we already explained how easy it is to perform in Datameer. The next step is to organize the data to your needs, which is also very easy to do in Datameer with different no-code operations:
- A no-code Filter operation that allows you to keep only the rows of data that have specific values or meet certain criteria, to whittle down the dataset,
- A no-code Sort operation that allows you to organize the data according to specific values or criteria, and
- A no-code Aggregation operation that allows you to aggregate data in multiple ways along different values or criteria without writing complex SQL code.
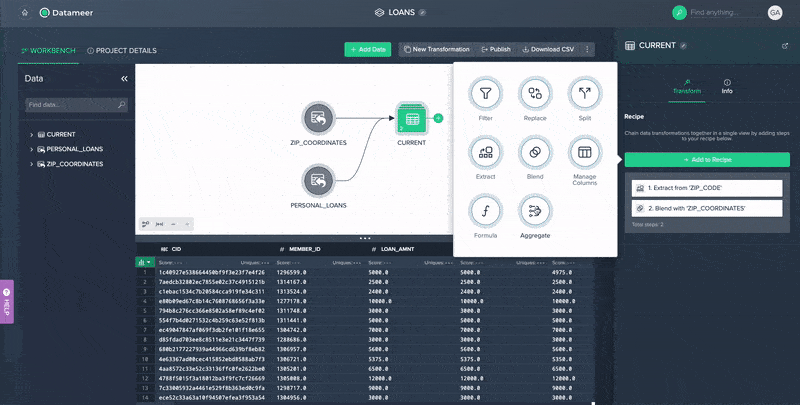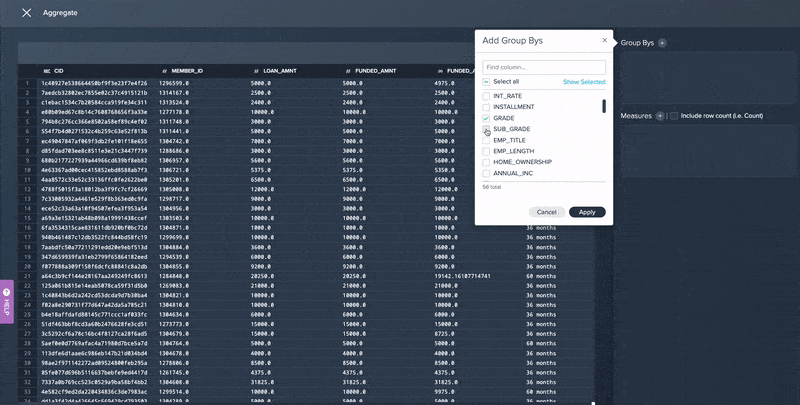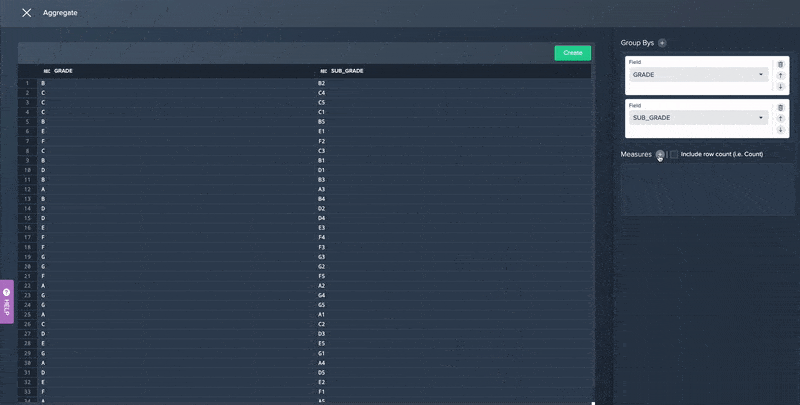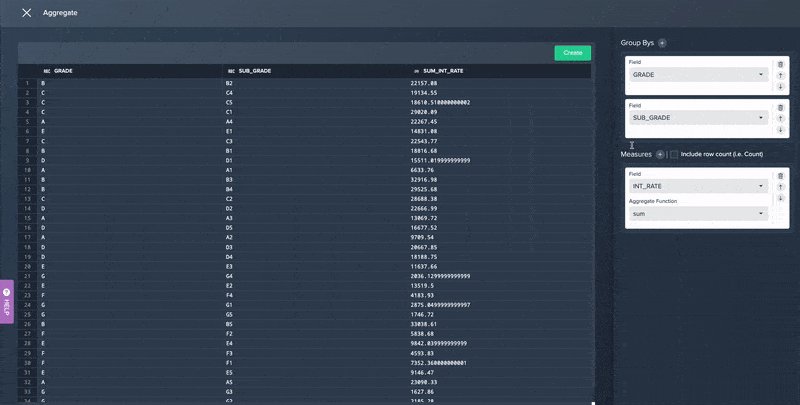
No Code Data Aggregation in Datameer
Derived Attributes
Derived attributes are fields added to a dataset that are calculated from other fields. The most commonly thought of derived attribute is Age – calculated by subtracting birthdate minus current date. Other derived attributes include date/time conversions (hour, day, month, quarter), time periods, time between, counts, and classifications (time bands, age bands, etc.).
Aggregation operations, which we showed above, are easy to do in Datameer and are essential to deriving count attributes. For other types of derived attributes, Datameer offers:
- An easy to use, formula builder wizard that allows one to create new calculated fields just like they were in Excel and without writing any SQL code, and
- A graphical Pivot wizard that allows one to pivot and group large datasets in their Snowflake data warehouse, again, just like they were in Excel and without writing any SQL code.
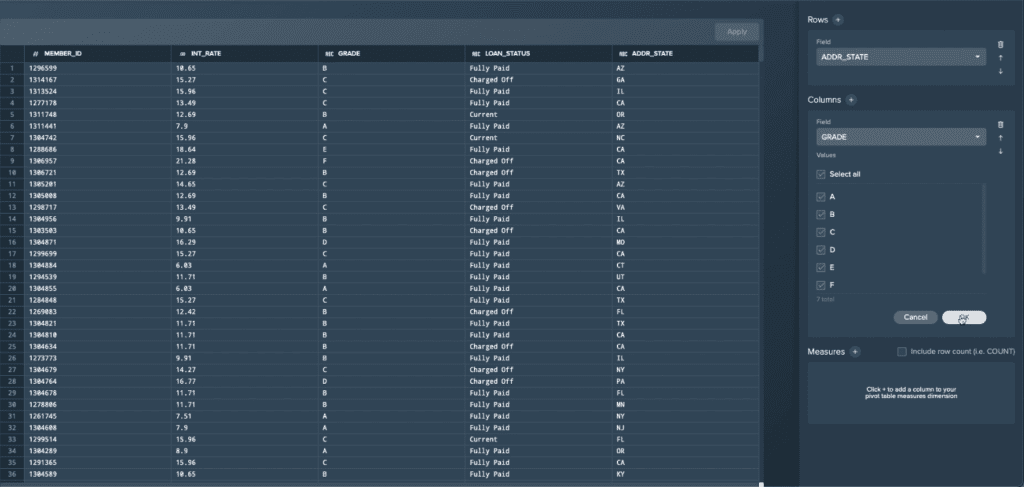
No-code, Wizard-driven Pivot in Datameer
Data Imputation
Some consider data imputation part of data cleansing, as it is the process of replacing values for missing or inconsistent data within fields. A prime example is estimating the value of a missing field based on other values.
Data cleansing is often the realm of data engineers, who may know a lot about the data but may not know the context by which the analytics are used. Therefore, data imputation may be better suited for transformations performed by data analysts, who better know what the analytics are targeting, and hence is better classified as data enrichment.
The easy-to-use Datameer formula builder can be used to help calculate values to fill in for missing or inconsistent values. In addition, Datameer also offers a no-code Replace operation that can be used to easily replace missing or inconsistent values in a dataset.
Entity Extraction
When one is using more complex unstructured or semi-structured data, multiple data values may be encoded within one field. To make the data useful, the values need to be extracted from one field, then exploded out into one or more new columns in the data.
For data extraction, Datameer offers two easy to use functions:
- A wizard-driven, no-code Extract operation that will extract values from a column and put the value in a new column,
- A no-code Split operation that allows a user to pull multiple sets of values from a column based on a specific delimiter or pattern and generate multiple new columns.
Data Enrichment Best Practices
There are five critical best practices for enriching your data that Datameer helps you keep for highly effective data enrichment:
- Support hybrid teams – Data enrichment is often one of the final data transformation tasks and is best left to the data analysts who best know how they want to use the data in the analytics at hand. Datameer’s hybrid SQL and no-code toolset allows any person, programmer and non-programmer, to enrich the data to their needs and produce highly effective datasets.
- Produce consistent results – A data enrichment task must be run the same way time and again, and produce the same results. Datameer gives you the ability to schedule dataflows to run on a consistent basis and will always apply the same exact functions/operations on the data, so there are no inconsistencies within the results.
- Assess the execution – You must be able to assess whether the process has run properly. To this end, Datameer provides deep audit trails of all data flows executed and transformations performed within the data flows, as well as the ability to inspect and explore resulting views.
- Completeness and variety – There many different ways in which data can be enriched according to the specific needs of the analytics at hand. To support this, Datameer offers a rich suite of transformation functions that allow for almost any form of data enrichment.
- Generality – Data enrichment should and could be applied to any dataset. Datameer offers a versatile data transformation tool that allows any form of data enrichment to be applied to any dataset in your Snowflake data warehouse.
Conclusion
Data enrichment is an often overlooked yet highly critical part of producing analytics-ready datasets. This is often because when designers decide what data to capture in applications, they are not privy to downstream analytics data requirements. In addition, analytics data needs will always change over time.
Therefore, it is critical to have a highly evolved, easy-to-use data transformation tool that allows any team member to transform and enrich data to their specific needs. This allows the analytics teams to be more responsive to the business, produce highly accurate analytics, and drive greater adoption of analytics.
About Datameer
Datameer’s SaaS data transformation platform focuses on the T – transformation – in your modern ELT data stack. Datameer is the industry’s first collaborative, multi-persona data transformation platform that is Snowflake-native. The multi-persona SQL code and no-code UI supports your hybrid team of programmers and non-programmers on a single platform to collaboratively transform and model data. Catalog-like data documentation and knowledge sharing facilitate trust in the data and crowd-sourced data governance. Native integration into Snowflake keeps data secure and lowers costs by leveraging Snowflake’s scalable compute and storage.
Are you interested in learning more about Datameer and how it can deliver agility and collaboration for the “T” in your modern ELT data stack without requiring you to add additional resources? Please visit our website to schedule a personalized preview with our team or sign up for a free trial .