HiveServer2
INFO
Note when using Hive 3: We are now converting all Datameer DATE columns to Hive TIMESTAMP and Hive DATE type data when exporting to HIVE 3 from the Datameer server time zone to UTC. And on import from Hive TIMESTAMP and Hive DATE back from UTC to Datameer server time zone. Never set the property "hive.parquet.timestamp.skip.conversion" to "TRUE". This would result in inconsistent data being stored in HIVE.
Configuring Hive Server2 as a Connection
Configuring a HiveServer2 connection is similar to configuring Hive.
To create a HiveServer2 connector:
- Click the + (plus) button at the top left of the File Browser and select Connection, or right-click on a folder, select Create New then select Connection.
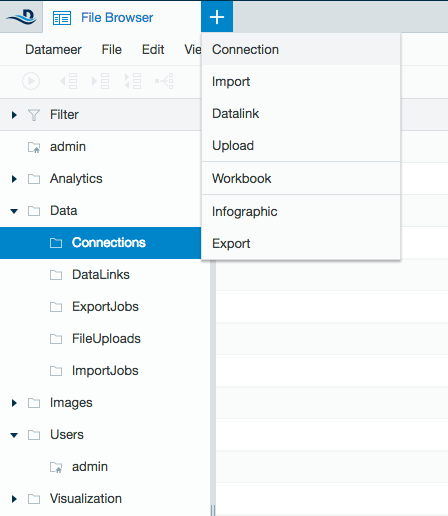
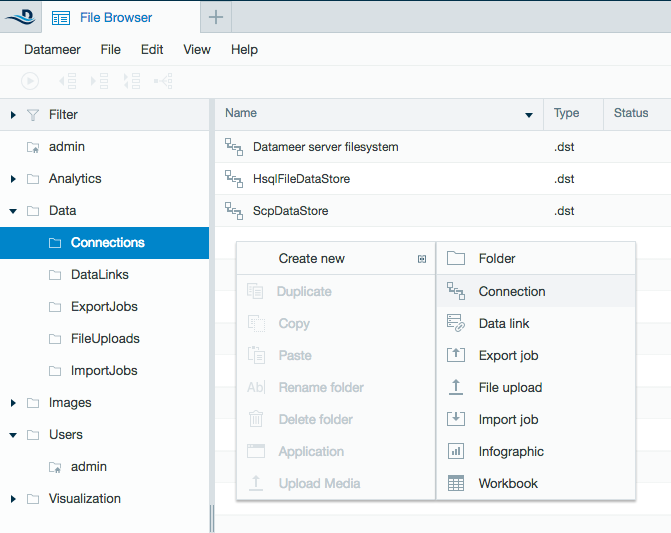
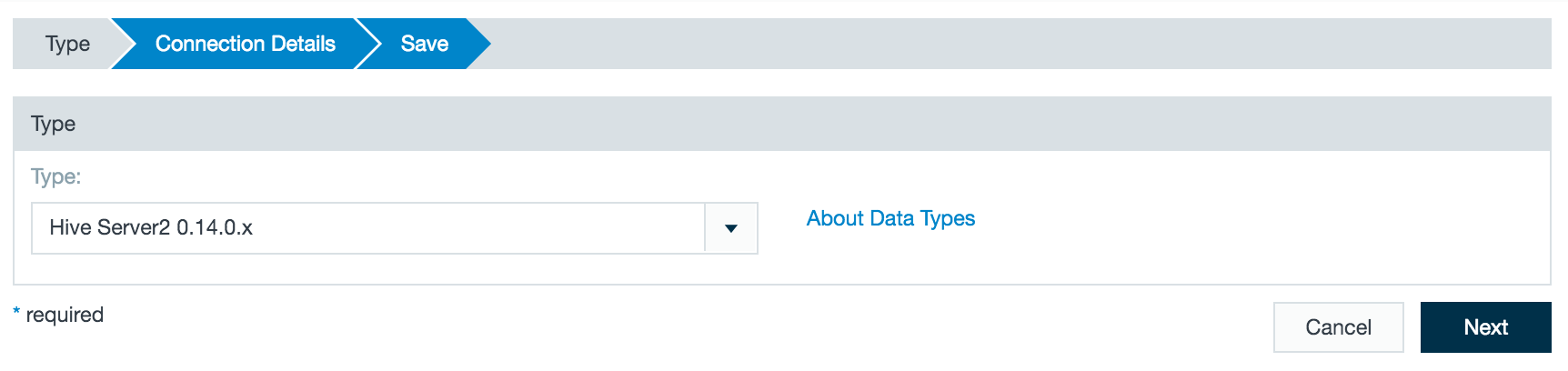
- From drop-down list, select Hive Server2 as the connection type. Click Next.
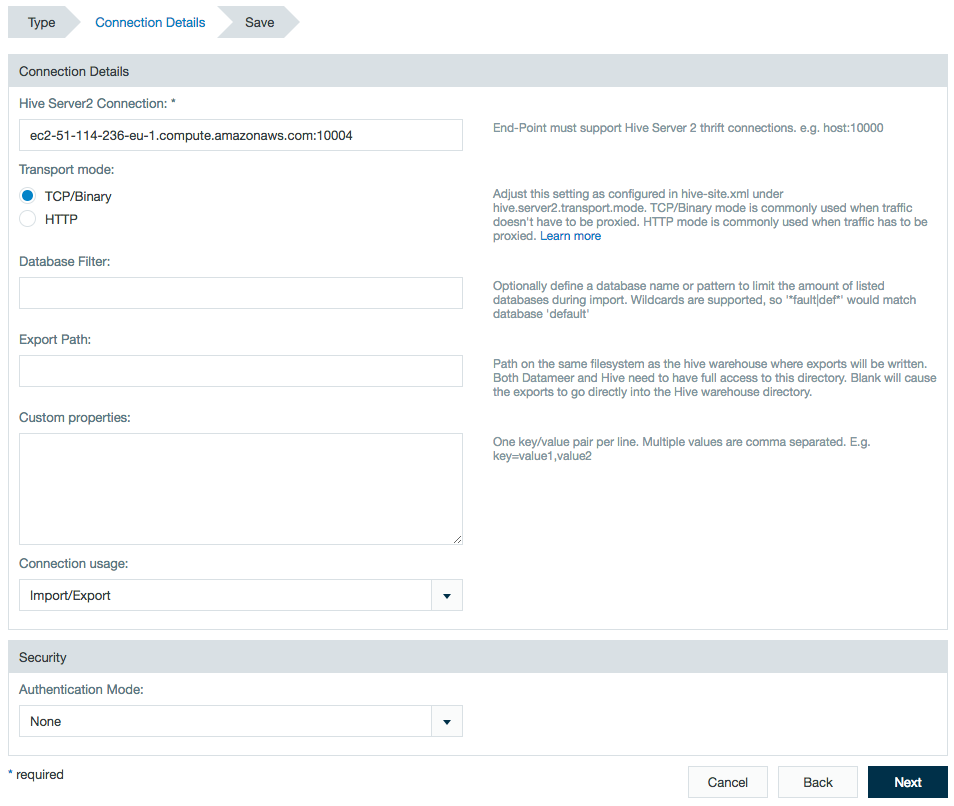
Enter the HiveServer2 connection address and port number.
Select TCP/Binary or HTTP as the transport mode. (Transport mode option is available as of Datameer v6.3)
- If selecting HTTP as the transport mode, the propertyhive.server2.thrift.http.pathhas the hardcoded value ofcliservice. Learn more at Apache Hive.
- HTTP mode using SSL is not supported.
- HTTP mode can only be used if Hive supports token based authentication . Hive versions >= 1.2 supports this feature.
Optional:
- Enter a database filter to limit the amount listed databases when importing with this connector.
- Enter an export path where exports from this connector are written.
- Enter any additional custom properties.If the database filter for a connection is updated, all import and export jobs using a prohibited database fail upon running.
Security
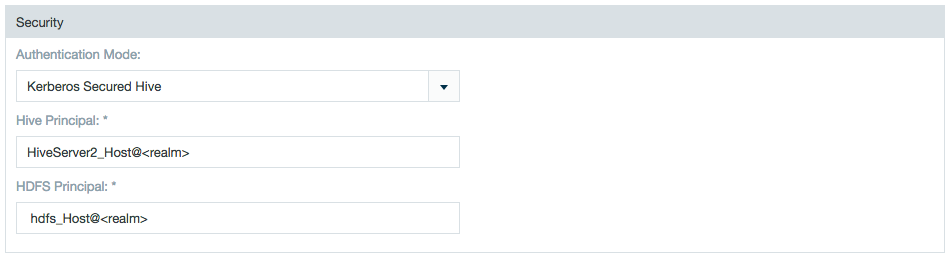
Kerberos
Select Kerberos Secured Hive and enter both the Hive and HDFS principals.
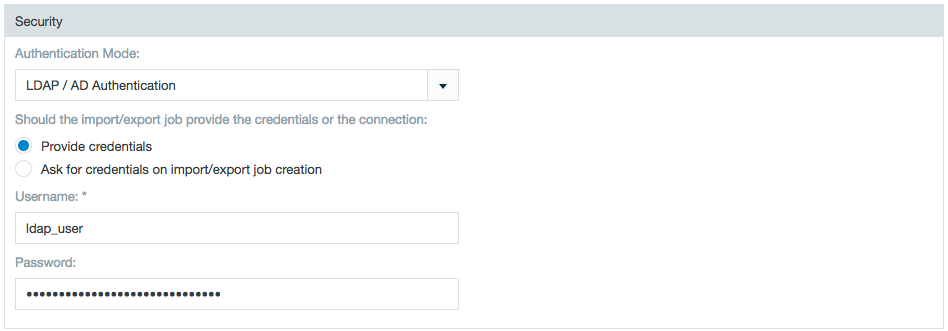
LDAP
Select LDAP/AD Authentication and select between having the HiveServer2 connector provide the authorization credentials or have the credentials provided by the individual import/export jobs.
Sentry
Datameer respects Sentry permissions from users running HiveServer2.
How Datameer and Sentry interact with users:
When you add an artifact though Datameer to Hive, it is added using the Datameer service account. The Datameer service account must has all permissions for Hive to authenticate with Sentry.
However, data is accessed on the Hive cluster using the Datameer user account. The Datameer user account must have permissions for the requested data in Hive as well as Datameer to authenticate with Sentry.
At the transport level, HiverServer2 has multiple connection methods available. Datameer currently supports the following binary connection methods:
SASL
- Non SSL
- NOSASL
- Kerberos
Plain
- Fill out a description and save the connector.
Importing Data with a HiveServer2 Connector
Configuring the import job wizard with a HiveServer2 connector follows the same procedure as importing from Hive.
The dialog itself provides more detailed descriptions. If you are unsure of the best choices, contact your Hive or Hadoop Administrator.
As of Datameer 7.5
Datameer is able to compute the partition location while importing data from a partitioned Hive table without needing to retrieve it from the HiveServer 2. This improves performance if the default partition location pattern is used. The setting can be made globally from the plugin configuration page, and the default value can be overwritten in the import job or data link wizard.
As of Datameer 7.5, Datameer Classic data field type mapping is removed and only Hive specific mapping is performed, where Datameer BigDecimal maps to Hive Decimal and Datameer Date maps to Hive TimeStamp.
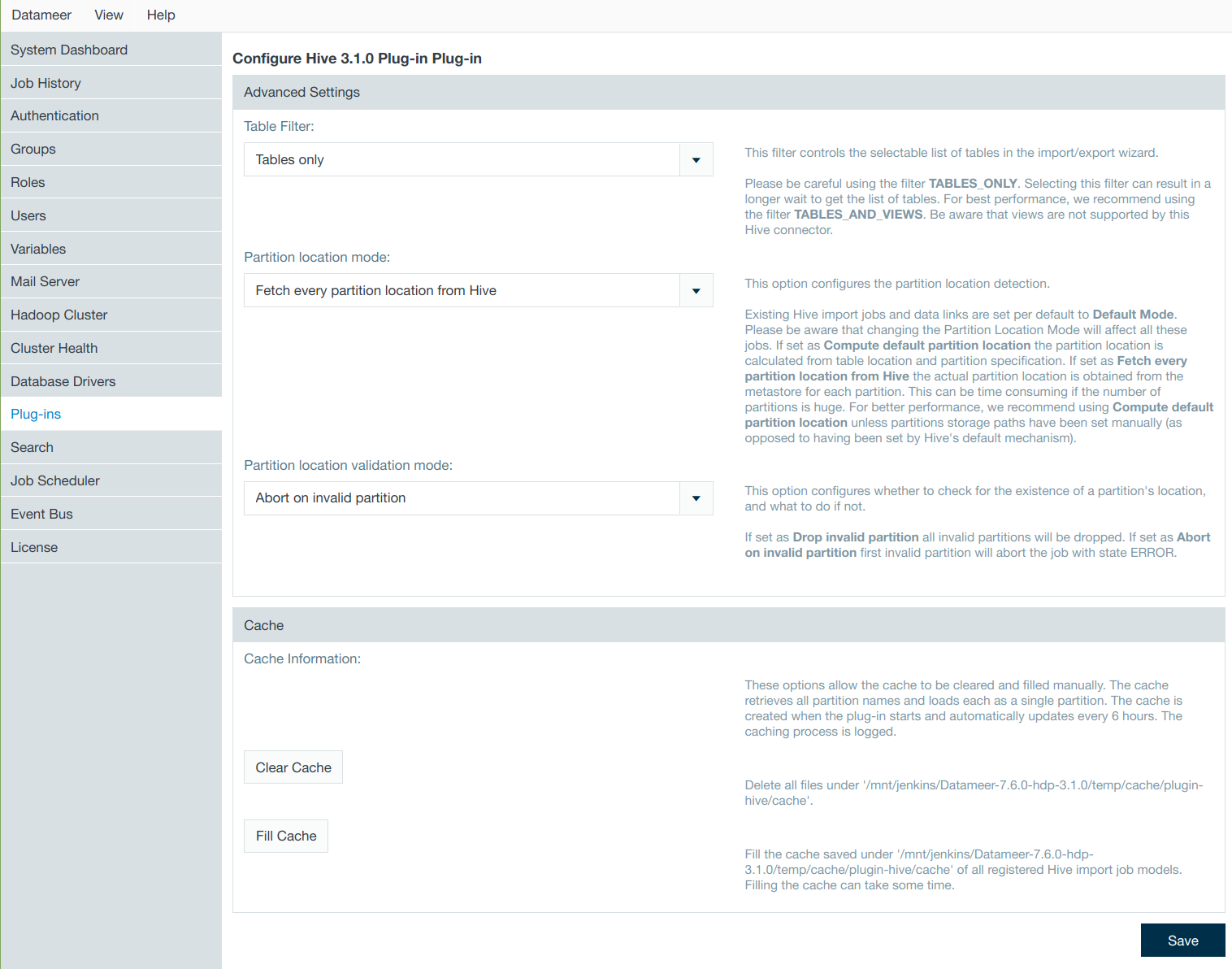
Configuring the Hive Plug-in
The Hive plug-in is provided per default with the installation of Datameer to import from and export to Hive servers. It can be found in the Admin tab by selecting Plug-ins from the menu.
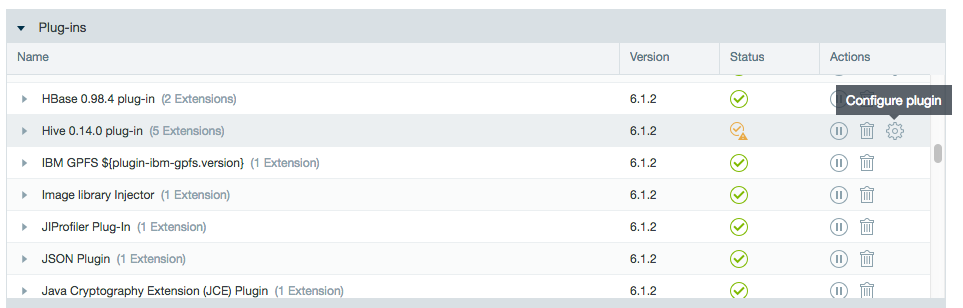
Click the cog icon in the Actions column to configure the plug-in properties.
Export Settings
There are options for configuring data field type mapping from Datameer to HiveServer2 upon export.
- In Datameer versions through 7.4, "Classic" is the default setting for the Hive plug-in. In Datameer versions 7.5+, Hive implicit mapping is used. Details of this mapping can be found under Exporting: Datameer Versions 7.5+ .
- Hive specific is similar to the default setting with the change that Datameer's BigDecimal is mapped to Hive's Decimal and Datameer's Date is mapped to Hive's Timestamp data type.
- BigDecimal
- New Table - Datameer exports the BigDecimal type to the Hive type Decimal with a precision (total number of digits) of 38 and a scale (number of digits to the right of the point) of 18.
- Existing Table - Datameer exports the BigDecimal type to the Hive type Decimal with the precision and scale defined on the Hive server.
- A maximum is set at a precision scale of (38,37).
- If an exported value doesn't fit within the precision/scale of either a new or existing table, a failure occurs.
- Date
- New Table - Datameer exports the Date type to the Hive type Timestamp.
- Existing Table - Datameer exports the Date type to the Hive type Timestamp/Date/String depending on what is defined on the Hive server.
- BigDecimal
The mode has no influence when exporting into an existing partitioned Hive table.
Cache
Datameer caches Java objects that represent partitions on HiverServer2. These partitions contain locations, columns names, and other information. Datameer stores these objects on a local disk. When Datameer needs to read Hive partitions it increases performance by using the stored cache instead of having to pull the same information each time it is needed.
The cached Hive partition data is created for all registered import job models when the plug-in starts and then updates automatically every 6 hours. Registration occurs when the import job or data link is created using the wizard as well as when the job is processed.
From the Hive plug-in configuration settings, you have the ability to clear the current cache or start filling it immediately without having to wait for the automated renewal.
- The cache can be cleared to remove stored partition data that is no longer being used and is decreasing performance.
- The cache can be manually filled before the auto update to cache new/changed Hive partition data to increase performance.
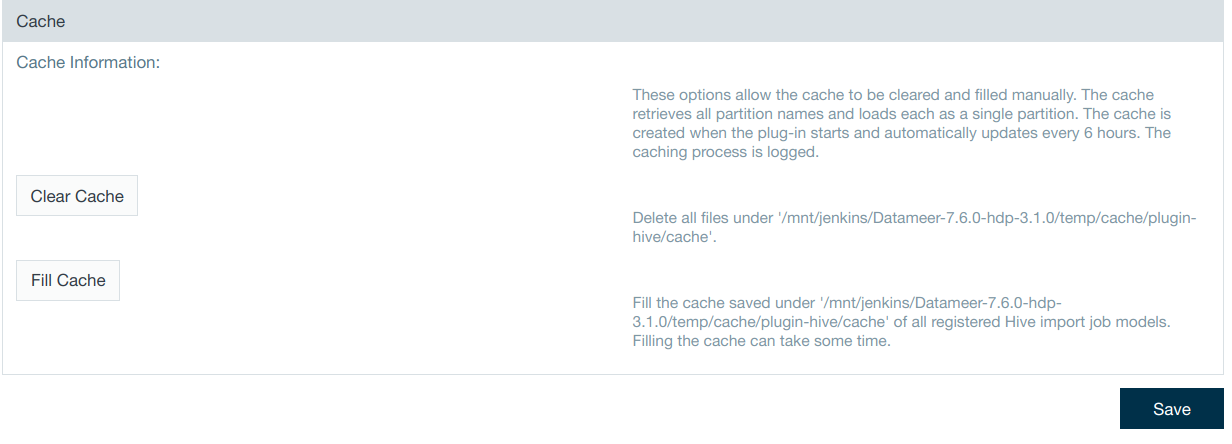
The feature is unavailable for HiveServer1.