Innovating the Three Most Influential Factors of Analytic Speed
- Datameer, Inc.
- February 22, 2018

Even before the era of computers and computing interfaces, Albert Einstein understood the value of user experience. Apple has certainly embraced the importance of user experience. With the continuous study of game flow and other user experience metrics, online gaming companies have an almost religious relationship with how customers use their products.
What if Albert Einstein’s quote was applied to you, the business or data analyst. What if you had a user experience that allowed you to learn from their data in such a way you could go about their tasks with enjoyment, not drudgery? This would create a quantum leap in speed, measured in terms of how fast you found the answers the business needs.
Speed should be measured not just on performance benchmarks but also in terms of how fast one completes a job – end to end. Three key factors impact this:
- How in-tune is the analytic workflow to how an analyst works?
- How fully self-service are the UI and UX?
- How is the analysis actually executed against the full data?
It’s these three factors that fueled our decision making when we scoped out what we’d introduce to you. Read on to find out not only what’s new, but more importantly, why it matters to you:
The Analytic Workflow: Reinvented
The analytic workflow is an underlooked yet vitally important aspect of speed. The “enjoyment” Albert Einstein referred to is majorly influenced by the workflow. If the analyst can “get in the zone,” similar to how gaming companies try to get their users into the flow zone (see graph below), finding answers from big data will be faster, simpler, and more enjoyable.
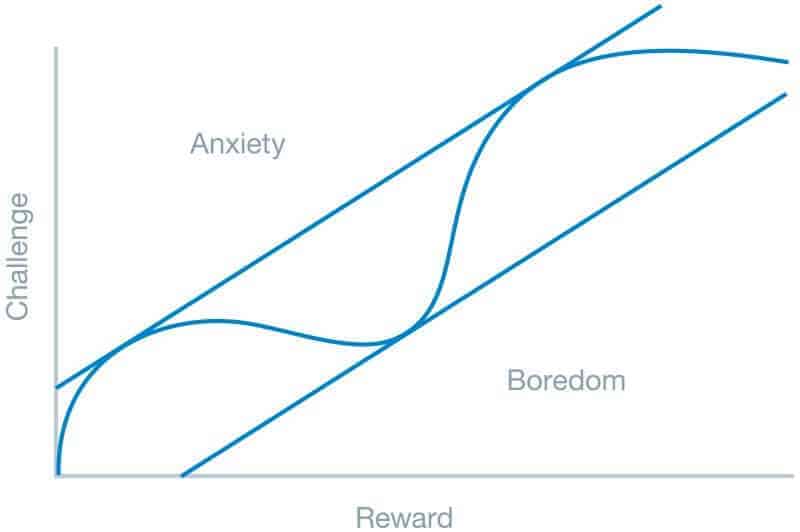
We’ve completely reinvented the analytic workflow because we know analysis is much faster in modern BI when it is iterative and fluid. Such a user experience feeds the experimentation process, which is how you perform data discovery. The traditionally sequential steps of data integration, preparation, analytics, and visualization are blended into an open, fluid interaction rather than a linear one.
Using fluid data discovery, you can experiment with each phase of the cycle. The different phases of the cycle open simultaneously, allowing you to make an iterative set of tweaks to any phases and directly see the upstream and downstream impacts. You can quickly run through experiments to find answers without ever having to switch context. Quickly and efficiently, you discover the answers you seek.
True Self-Service
Analytic software products will often put barriers in the analysis path by forcing analysts to drop down and code at certain points in time. This causes a shift in context, tools, and/or team members that disrupts the workflow process.
Many platforms have gaps such as these, which you should be aware of, including:
- Some platforms require you to build a data lake, write code to ingest all your data into Hadoop before it can be analyzed. This creates delays when trying to add new data to the analysis process.
- Other platforms will force you to model your data, writing Spark SQL to create analysis data views. This breaks the workflow and creates delays in the integration and preparation steps.
- Specific bridges, such as OLAP on Hadoop or SQL connections to Spark, will force you to write programs that pre-structure your data to fit a specific static model. This also breaks the workflow and creates delays in the integration and preparation steps.
Datameer is completely self-service, providing a means to perform all the analysis steps within a common iterative process by a single analyst without dropping down and code. The completely redesigned UI is streamlined and purposely makes your data the center of your experience.
Click here to learn more about how the data discovery user experience was completely re-imagined to streamline your path to answering questions.
Ensuring the Fastest Execution of the Analysis – Every Time
And of course, how fast the engine can crunch through the data is also critical. This involves using the most appropriate execution engines, including Spark, to handle the right analytic workload at the right time. But it also means that the technical complexity of how the job is executing it should be hidden from you. You should only need to know that it executes quickly and efficiently, so your experimental workflow is not inhibited.
Many products can connect to or embed Spark as the execution engine. But the technical complexity of using Spark is NOT hidden. This creates the need to understand how to use Spark, and oftentimes how to program in Spark. It also creates future upgradability problems as Spark changes or new execution engines emerge.
By adding Spark to Smart Execution, you’re guaranteed a modern BI platform that optimizes the latest and greatest execution engines while abstracting the technical complexities. That gives you the best of both worlds – fast analytic job execution and future-proofing for easy upgrades to new technologies as they mature on the market.
Click here to learn how Datameer leverages powerful execution engines such as Spark while hiding technical complexities.


