Low-Code Data Transformation Pipelines
Leverage the best of No-Code and SQL to integrate, enrich, clean, and automate your data transformations with unmatched speed and simplicity. Enterprise grade. Cloud-Native.

 Trusted by top global enterprises
Trusted by top global enterprises

Do it all on one platform



Keeping all of your data in one place, on Snowflake
Datameer was purpose built for Snowflake to streamline your data processes, reducing duplicate work and keeping your data accessible.
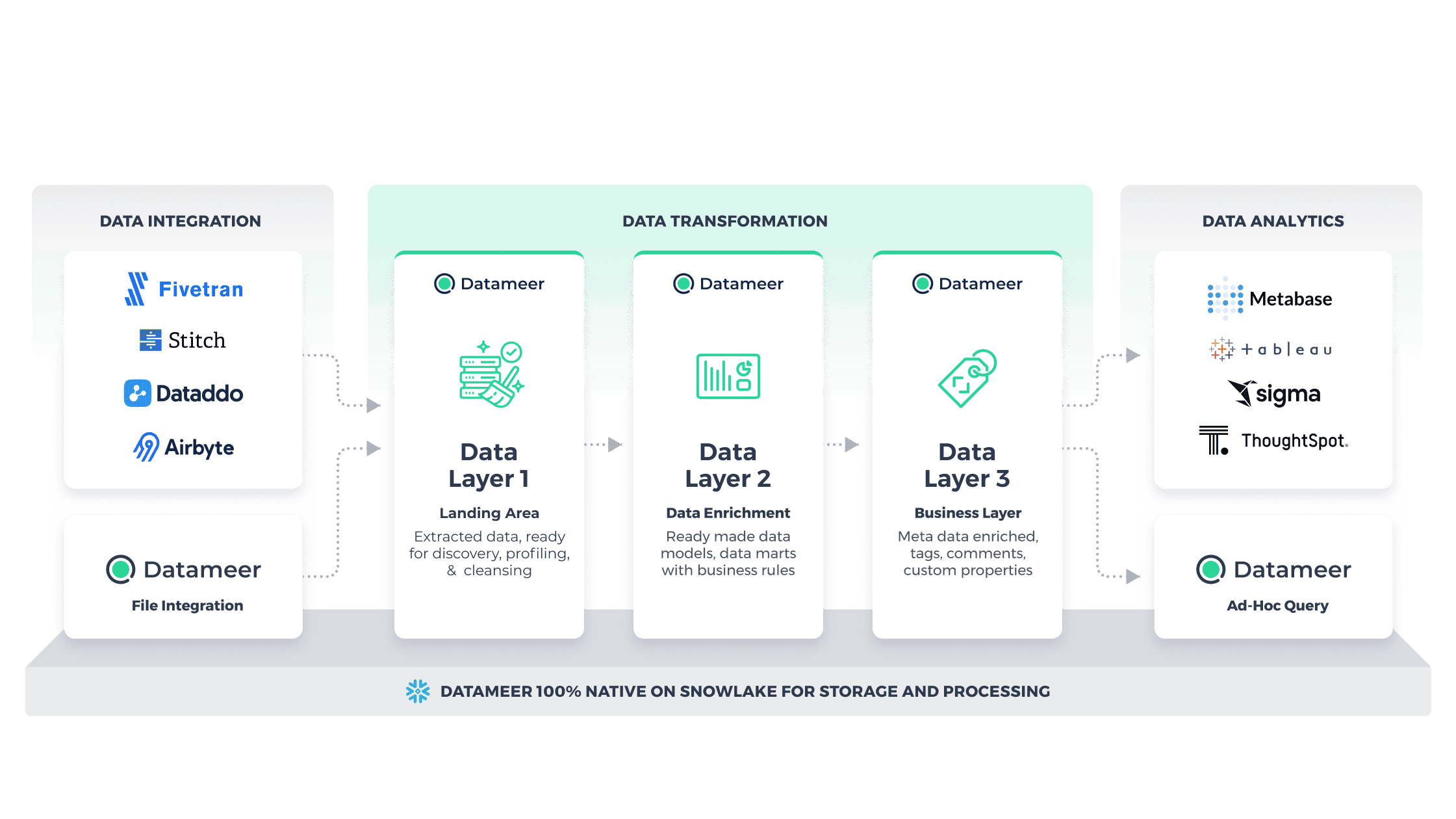
Modern BI Architecture with Datameer
Datameer integrates seamlessly with your modern data stack, offering advanced data transformation, enrichment, and automation capabilities to drive unparalleled depth in insights.
Collaborate with your team




Get started in minutes
- Cost Savings: No installation, maintenance, infrastructure, or IT labor costs.
- Instant User Activation: Users can start in seconds.
- Continuous Innovation: Access new features seamlessly.
- Universal Accessibility: Works on any desktop, laptop, or OS.
Real-World Results From Datameer Users
Build Your Modern Data Stack in One Day
Learn from our experts how to get started with your data journey
Get the guide